







机器学习 DNN 手写识别
本文是关于经典深度神经网络DNN的应用手写识别的思路样例。
一、题目
请描述一个深度神经网络模型解决实际问题的例子。
包括问题描述,输入输出数据,训练、测试数据集,深度网络模型结构图,损失函数,训练方法,以及其他需要说明的内容。
二、问题描述
下面将描述一个深度神经网络的典型经典例子:手写数字识别(OCR)。
⼈类视觉系统是世界上众多奇迹之一。下面的手写数字序列:

大多数人毫不费力就能够认出这些数字为 504192。识别手写数字不是一件简单的事。尽管⼈类在理解我们眼睛展示出来的信息上非常擅长,但如果你尝试写出计算机程序来识别诸如上面的数字,就会明显感受到视觉模式识别的困难。看起来人类一下子就能完成的任务变得特别困难。关于我们识别形状——“9 顶上有一个圈,右下方则是一条竖线”这样的简单直觉——实际上算法上就很难轻易表达出来了。而在你试着让这些识别规则越发精准时,就会很快陷入各种混乱的异常或者特殊情形的困境中。实现一个可以识别手写数字的神经网络。这个神经网络不需要人类帮助便可以超过 96% 的准确率识别数字。实际上,最优的商业神经网络已经足够好到被银行和邮局分别用在账单核查和识别地址上了。
二、输入输出数据

1、输入数据
一系列手写的数字,例如:
2、输出数据
识别出的数字:504192
三、训练、测试数据集
使用经典的MNIST 数据集作为数据源。MNIST 数据分为两个部分。第一部分包含 60,000 幅用于训练数据的图像。这些图像扫描⾃250 ⼈的手写样本。这些图像是28 × 28 ⼤小的灰度图像。第二部分是 10,000 幅用于测试数据的图像,同样是 28 × 28 的灰度图像。
训练集测试集样例

四、深度网络模型结构图
我们可以把识别手写数字的问题分成两个子问题。首先,我们希望有个方式把包含许多数字的图像分成一系列单独的图像,每个包含单个数字。例如,我们想要把图像
分成六个单独的图像

一旦图像被分割,那么程序需要把每个单独的数字分类。例如,我们想要我们的程序能识别上面的第一个数字是 5。

有很多途径可以解决分割的问题。一种方法是尝试不同比分割方式,用数字分类器对每一个切分片段打分。如果数字分类器对每一个片段的置信度都较高,那么这个分割方式就能得到较高的分数;如果数字分类器在一或多个片段中出现问题,那么这种分割方式就会得到较低的分数。这种方法的思想是,如果分类器有问题,那么很可能是由于图像分割出错导致的。这种思想以及它的变化形式能够比较好地解决分割问题。因此,与其关心分割问题,我们不如把精力集中在解决第二个问题即分类单独的数字。
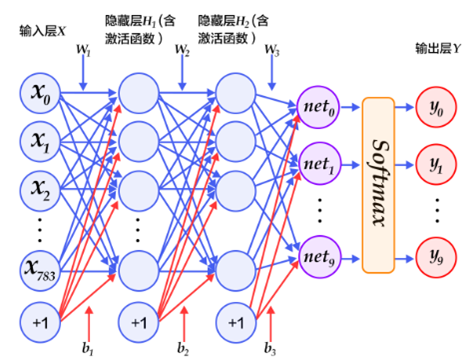
我们可以使用一个三层神经网络来识别单个数字:
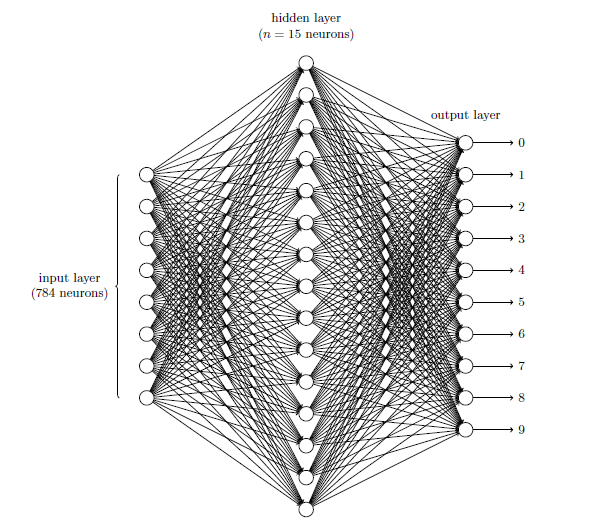
标准的DNN的模型结构:
网络的输入层包含给输入像素的值进行编码的神经元。我们给网络的训练数据会有很多扫描得到的 28 × 28 的手写数字的图像组成,所有输入层包含有 784 = 28 × 28个神经元。为了简化,上图中我已经忽略了 784 中⼤部分的输入神经元。输入像素是灰度级的,值为 0.0 表示白色,值为 1.0 表示黑色,中间数值表示逐渐暗淡的灰色。
网络的中间层是隐藏层。我们用 n 来表示神经元的数量,我们将给 n 实验不同的数值。示例中用一个小的隐藏层来说明,仅仅包含 n = 15 个神经元。
网络的输出层包含有 10 个神经元。如果第一个神经元激活,即输出$\approx1$,那么表明网络认为数字是一个 0。如果第二个神经元激活,就表明网络认为数字是一个 1。依此类推。更确切地说,我们把输出神经元的输出赋予编号 0 到 9,并计算出那个神经元有最高的激活值。比如,如果编号为 6 的神经元激活,那么我们的网络会猜到输入的数字是 6。其它神经元相同。
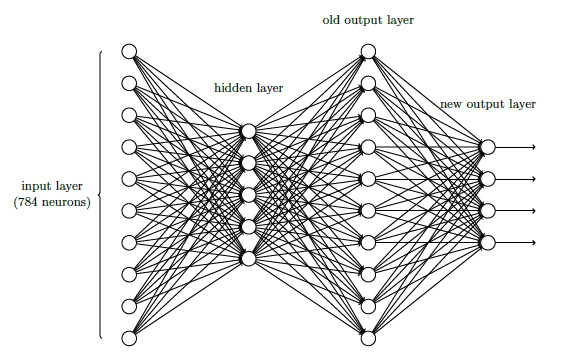
这里使用 10 个输出神经元,因为任务是能让神经网络告诉我们哪个数字(0, 1, 2, . . . , 9 )能和输入图片匹配,但是使用 4 个输出神经元,即把每一个当做一个二进制值,结果取决于它的输出更靠近 0 还是 1 。四个神经元足够编码这个问题了,因为 24 = 16 ⼤于 10 种可能的输入。但是10 个输出神经元的神经网络比 4 个的识别效果更好。
在上述的三层神经网络加一个额外的一层就可以实现按位表示数字。额外的一层把原来的输出层转化为一个二进制表示:
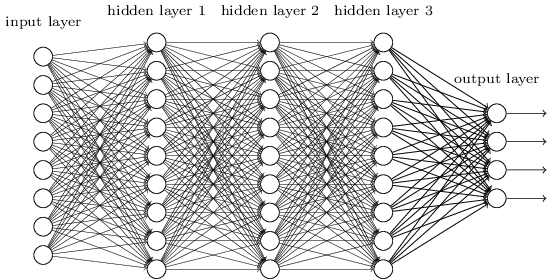
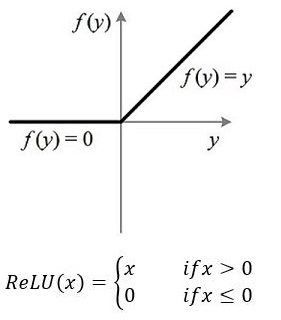
将上述网络详细展开来说,我们可以选择两个大小为100的隐层和一个大小为10的输出层,因为MNIST数据集是手写0到9的灰度图像,类别有10个,所以最后的输出大小是10。隐层的激活函数可以使用ReLU,最后输出层的激活函数是Softmax,所以最后的输出层相当于一个分类器。加上一个输入层的话,多层感知器的结构是:输入层–>隐层–>隐层–>输出层。
五、损失函及训练方法
我们使用DNN反向传播算法和梯度下降算法进行学习训练。我们将用符号$x$来表示一个训练输入。为了方便,把每个训练输入$x$看作一个表示$28\times28=784$维的向量。每个向量中的项目代表图像中单个像素的灰度值。我们用$y=y(x)$表示对应的期望输出,这里$y$是一个 10 维的向量。例如,如果有一个特定的画成6的训练图像$x$,那么$y(x) = (0, 0, 0, 0, 0, 0, 1, 0, 0, 0)^T$则是网络的期望输出。
我们希望有一个算法,能让我们找到权重和偏置,以⾄于网络的输出$y(x)$能够拟合所有的训练输入$x$。为了量化我们如何实现这个目标,我们定义一个代价损失函数:
$$
C(w,b)\equiv{\frac{1}{2n}}\sum_x||y(x)-a||^2
$$
这里$w$表示所有的网络中权重的集合,$b$是所有的偏置,$n$是训练输入数据的个数,$a$是表示当输入为 $x$时输出的向量,输出$a$取决于$x$,$w$和$b$,求和则是在总的训练输入$x$上进行的。符号$||v||$是指向量 v 的模。我们的训练算法的目的是最小化权重和偏置的代价函数$C(w,b)$。换句话说,我们想要找到一系列能让代价尽可能小的权重和偏置。
也可以使用的是交叉熵损失函数,该函数在分类任务上比较常用。定义了一个损失函数之后,还有对它求平均值,训练程序必须返回平均损失作为第一个返回值,因为它会被后面反向传播算法所用到。同时我们还可以定义一个准确率函数,这个可以在我们训练的时候输出分类的准确率。
$$
H(p,q)=-\sum_{i=1}^{n}p(x_i)\log(q(x_i))
$$
梯度下降算法的基本步骤:

六、总结
上述神经网络在测试集的准确度能达到95%左右,非常准确。
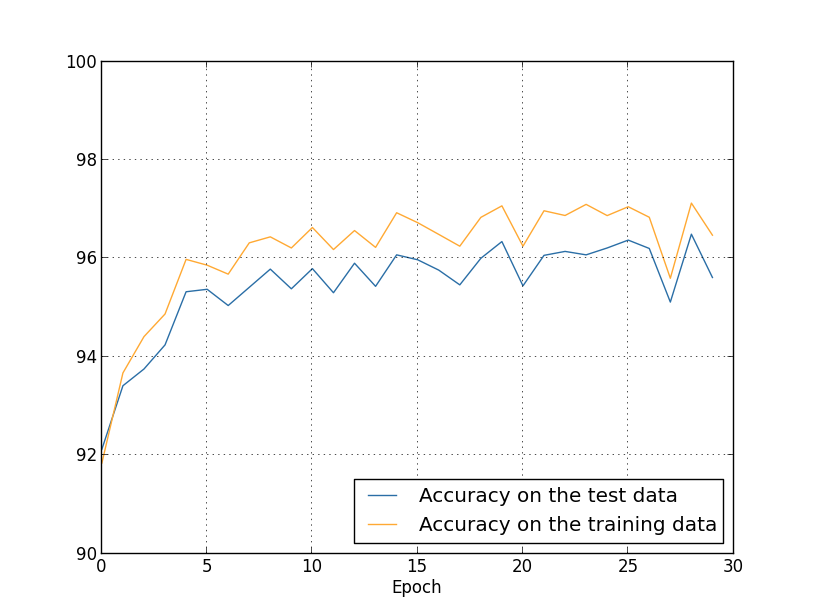
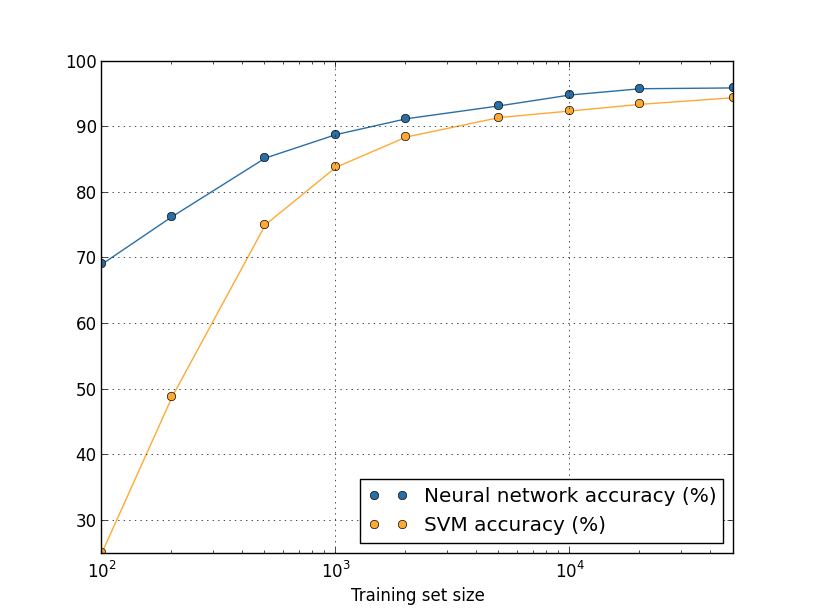
相较于SVM,准确度和性能均有较大提升。
深度神经网络(Deep Neural Networks,DNN)是一个非常有前景和创新的研究方向。除了手写识别(OCR),还有各个行业的经典样例,比如:图像方面的黑白照片变彩色照片的图像着色(LetThereBeColor)、图像风格化,将一幅图像的内容与另一幅图像的风格相结合(neural-style)、通过深度学习极大提高模糊图片的分辨率(srez)、实时捕获面部表情,调换到另外一个人的面部(Face2Face)、雅虎出品的成人图片分类器(open_nsfw)、成人视频分类器(Miles Deep)等等,就不一一列举了。总之深度神经网络和深度学习给出了在图像识别、语音识别和自然语言处理领域中众多问题的最好解决方案,重要性不言而喻。

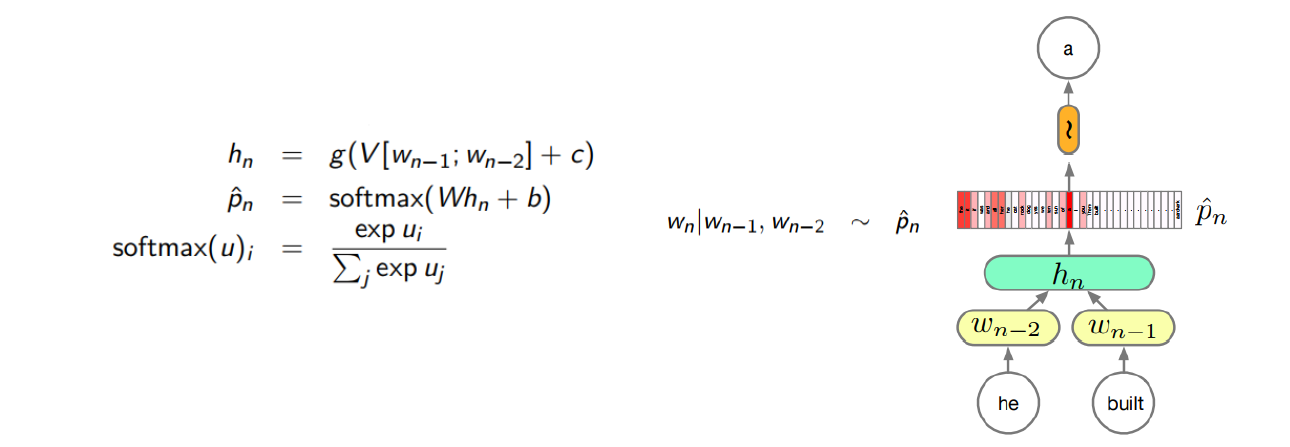
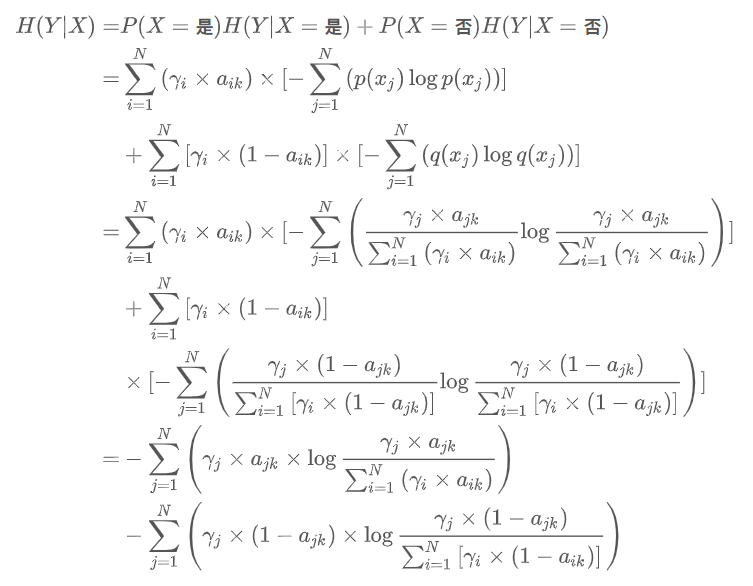
本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议

