







大数据 习题
自己随便整理了一下在学习“大数据”时遇到的一些习题,易错点之类的。
1、关于Spark中task,block,partition,split,core的关系
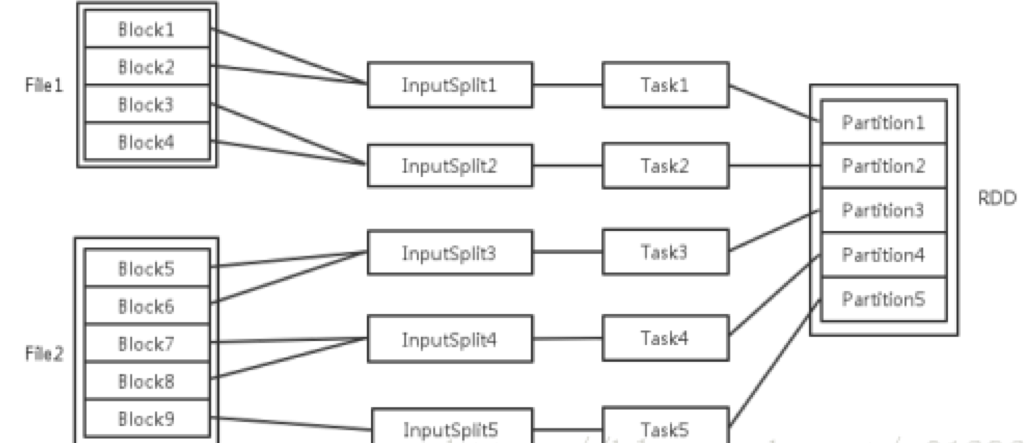
每一个过程的任务数,对应一个inputSplit, Partition输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
每个节点可以起一个或多个Executor。
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
每个Task执行的结果就是生成了目标RDD的一个partiton。
Task被执行的并发度 = Executor数目$\times$每个Executor核数(=core总个数)
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
- RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
比如:
RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的原因。
2、HDFS体系架构
HDFS采用了主从(Master/Slave)结构 模型,一个HDFS集群是由一个 NameNode和若干个 DataNode 组成的。其中 NameNode 作为主服务器,管理文件系统的命名空间和客户端对文件的 访问操作;集群中的 DataNode 管理存储的数据。HDFS 允许用户以文件的形 式存储数据。从内部来看,文件被分成 若干个数据块,而且这若干个数据块存 放在一组 DataNode 上。NameNode 执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体 DataNode 的映射。 DataNode 负责处理文件系统客户端的文件读写请求,并在 NameNode 的统 一调度下进行数据块的创建、删除和复制工作。
3、HDFS的读操作流程
- 初始化FileSystem,然后客户端用函数 open()打开文件。
- FileSystem调用元数据节点,得到数据 块信息,并对每一个数据块、元数据节点返回,保存数据块的数据节点地址。
- 客户端调用Stream的read()函数开始读 取数据。
- FSDataInputStream连接保存此文件第 一个数据块的最近的数据节点Datanode, data从数据节点读到客户端。
- 当第一个数据块读取完毕时, FSDataInputStream关闭和此数据节点的 连接,然后连接此文件下一个数据块的 最近的数据节点。
- 当客户端读取完毕数据的时候,调用 FSDataInputStream的close()函数,关闭连接。
4、HDFS的写操作流程

5、习题








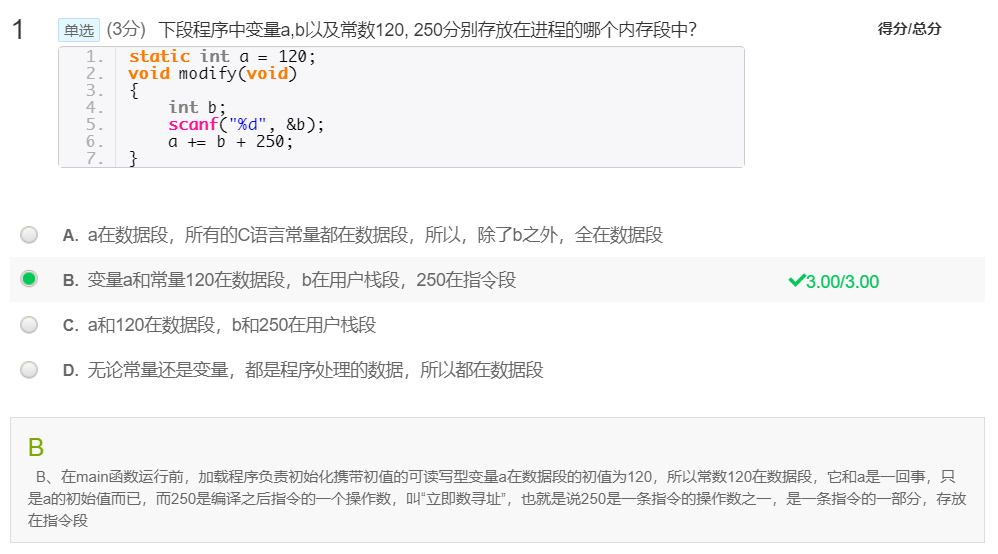 Linux MOOC习题 11~15章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的,接上文Linux MOOC习题 6~10章。
Linux MOOC习题 11~15章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的,接上文Linux MOOC习题 6~10章。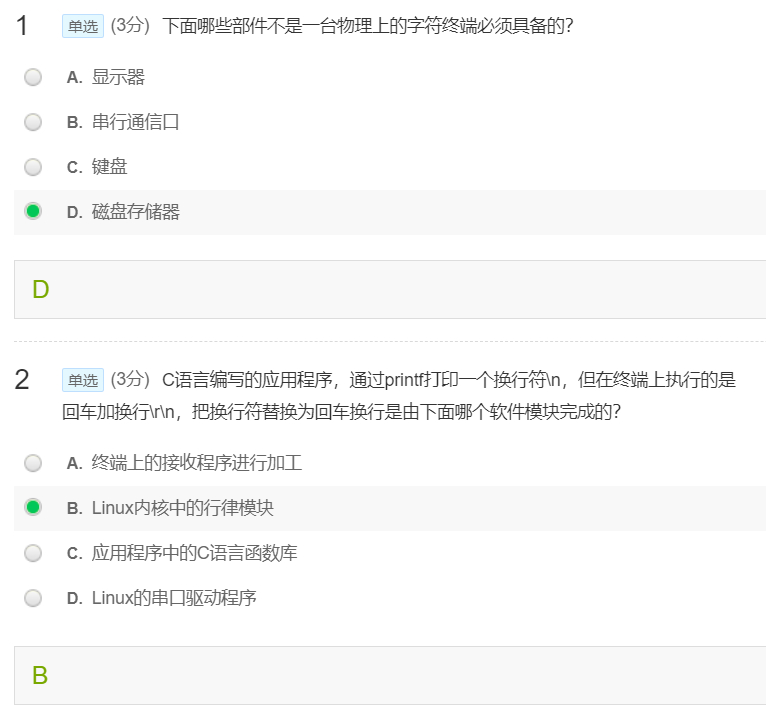 Linux MOOC习题 1~5章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的。
Linux MOOC习题 1~5章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的。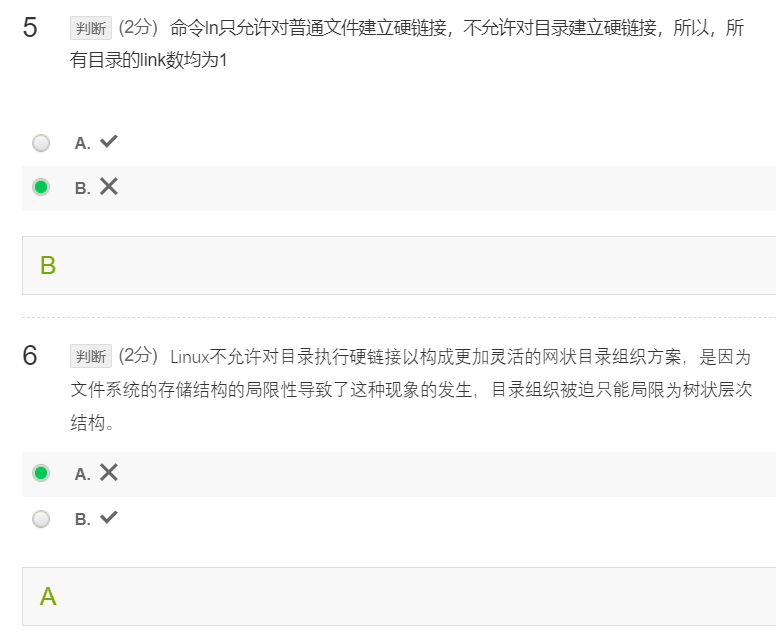 Linux MOOC习题 6~10章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的,接上文Linux MOOC习题 1~5章。
Linux MOOC习题 6~10章自己随便整理了一下在学习Linux网课时遇到的一些习题,易错点之类的,接上文Linux MOOC习题 1~5章。 现代交换原理 MOOC习题 1~4章自己随便整理了一下在学习“现代交换原理”网课时遇到的一些习题,易错点之类的。
现代交换原理 MOOC习题 1~4章自己随便整理了一下在学习“现代交换原理”网课时遇到的一些习题,易错点之类的。 现代交换原理 MOOC习题 5~6章自己随便整理了一下在学习“现代交换原理”网课时遇到的一些习题,易错点之类的。接上一部分现代交换原理 MOOC习题 1~4章。
现代交换原理 MOOC习题 5~6章自己随便整理了一下在学习“现代交换原理”网课时遇到的一些习题,易错点之类的。接上一部分现代交换原理 MOOC习题 1~4章。本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://666wxy666.github.io/2020/06/18/%E5%A4%A7%E6%95%B0%E6%8D%AE-%E4%B9%A0%E9%A2%98/

