







机器学习 实验 RNN 为baby起名字
本文是关于经典RNN的应用为baby起名字的代码实现。
一、任务定义
采用 RNN 为小 Baby 起个英文名字吧
神经网络语言模型,即通过神经网络,计算一项自然语言(例如一条句子)的出现概率,或者根据上文中的词推断句子中某个词的出现概率。例如,下图采用了一个具有一个输入层、一个隐藏层和一个输出层的 MLP 网络,建模三元文法模型:
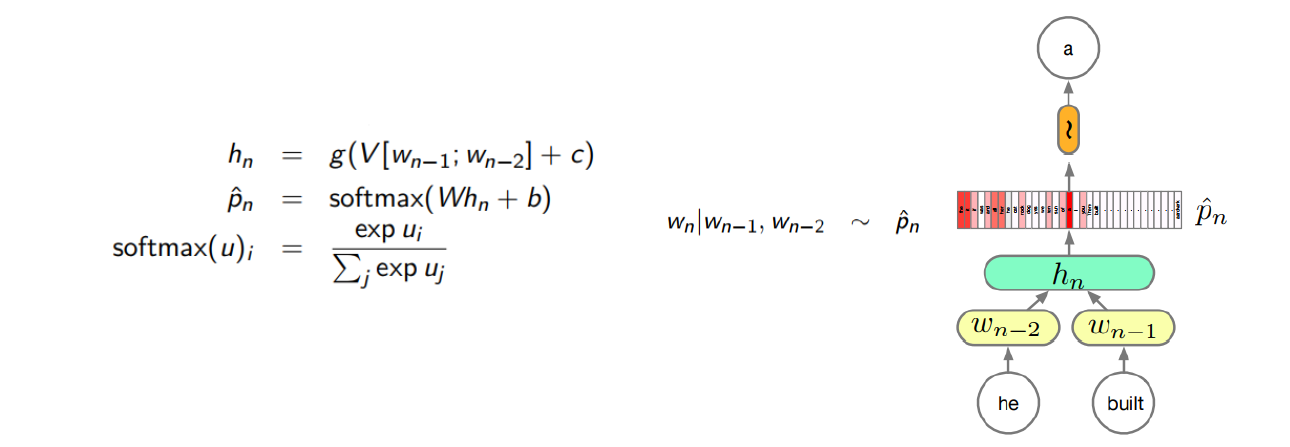
本作业提供了8000多个英文名字,试训练一个环神经网络语言模型,进而给定若干个开始字母,由语言模型自动生成后续的字母,直到生成一个名字的结束符。从模型生成的名字中,挑选你最喜欢的一个,并采用一种可视化技术,绘制出模型为每个时刻预测的前5个最可能的候选字母。
事实上,你也可以给定结尾的若干个字母,或者随意给出中间的若干个字母,让 RNN 补全其它字母,从而得到一个完整的名字。因此,你也可以尝试设计并实现一个这样的 RNN 模型,从模型生成的名字中,挑选你最喜欢的一个,并采用可视化技术,绘制出模型为每个时刻预测的前5个最可能的候选字母。
二、输入输出
1、输入
male和female数据集作为训练集。
【PS】注意,两个数据集的格式必须是一行一个英文名字,不能有其他文字说明,在使用前请先将male.txt和female.txt中的文字说明删除,例如:
超参数总迭代次数,打印精度(每隔多少次迭代打印一次损失日志),绘图精度(每隔多少次迭代求和取平均作为一个数据点)。
(类别,姓名的起始字母)对。
2、输出
- RNN神经网络模型。
- 该模型的损失等日志信息。
- 该模型的损失-(迭代次数/画图精度)函数图像。
- 根据这个神经网络模型和输入的(类别,姓名的起始字母)对生成的姓名。
三、实验环境
硬件:
- 处理器:Intel i7 7700HQ
- 显卡:NVIDIA GeForce GTX 1050 Ti
- 内存:16GB
软件:
编程语言:
Python 3.7(Anaconda3)
模块:
- pytorch 1.5
- numpy 1.18.1
- matplotlib 3.1.3
编译器:
PyCharm 2020.1.1 (Professional Edition)
Build #PY-201.7223.92, built on April 30, 2020
For educational use only.
Runtime version: 11.0.6+8-b765.40 amd64
VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Windows 10 10.0
GC: ParNew, ConcurrentMarkSweep
Memory: 725M
Cores: 8
Registry: ide.balloon.shadow.size=0
Non-Bundled Plugins: com.dubreuia, GrepConsole, Statistic, com.chrisrm.idea.MaterialThemeUI, org.intellij.gitee, com.mallowigi, com.wakatime.intellij.plugin, mobi.hsz.idea.gitignore, net.vektah.codeglance, tanvd.grazi, com.jetbrains.intellij.datalore, izhangzhihao.rainbow.brackets, cn.yiiguxing.plugin.translate, org.nik.presentation-assistant
四、方法描述
1、数据集处理
对老师的male.txt和female.txt数据集进行处理,保证每行只能由一个姓名,不得出现其他类似下图的说明信息。
我们将行分割成数组, 并把 Unicode 转换成 ASCII 编码, 最后放进一个字典里 {language: [names ...]}
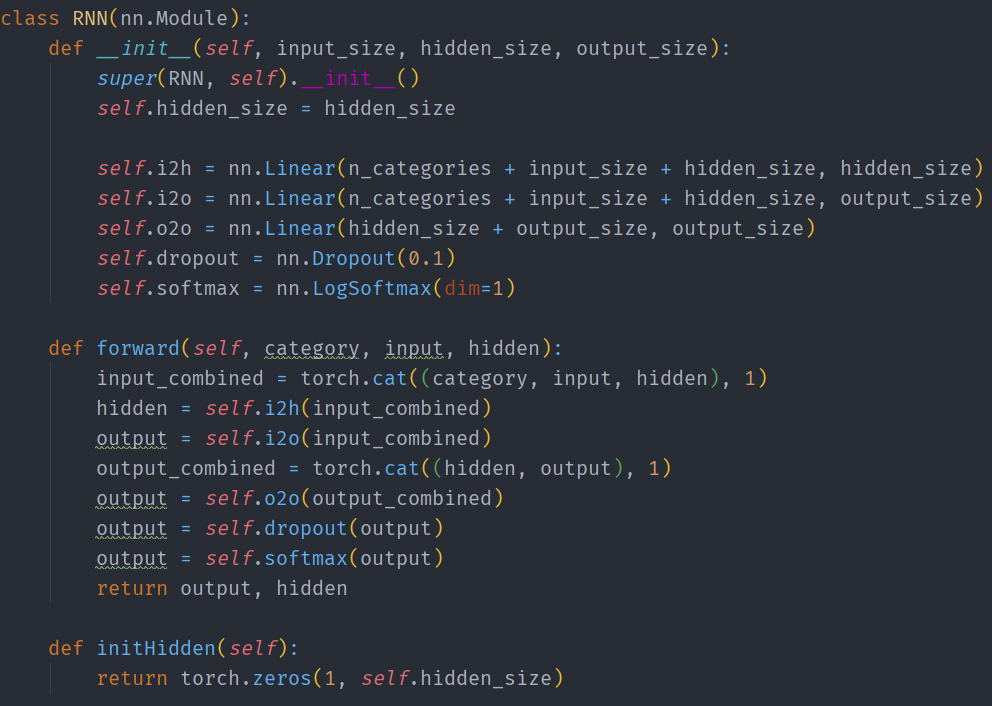
2、创建网络
输出设定为下一个字母的概率,采样测试的时候,概率最大的输出字母被当做下一个输入。
输出层采用softmax函数,为了让网络更加有效工作,添加了第二个线性层o2o(在合并了隐藏层和输出层的后面)。还有一个 Dropout 层,使输入的部分值以给定的概率值随机的变成 0(这里概率取0.1), 为了模糊输入以防止过拟合,在网络的最末端使用它,从而故意添加一些混乱和增加采样的多样化。
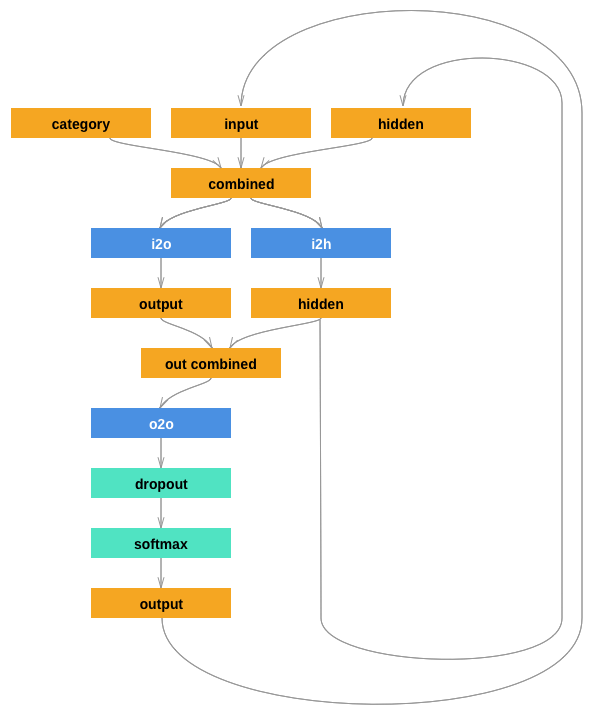
3、训练前的准备
首先读取文件,产生随机的(类别,文件行[也就是姓名])对。对每一个时间点(也就是说在训练集中词的每个字母)网络的输入是(类别,当前字母,隐藏层状态),输出是(下一个字母,下一个隐藏层状态)。
因为在每一步,我们从当前的字母预测下一个字母,这样的字母对是在原有行中连续字母的集合,例如:

类别张量是一个大小为$1\times{categories}$的one-hot tensor张量,在训练的每一个时间点把它提供给网络。
4、开始训练
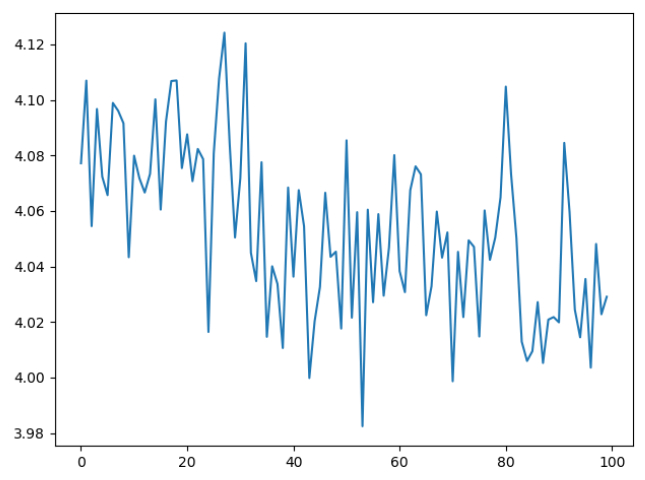
使用自动求导(autograd)辅助计算损失。循环调用train,每隔一段时间打印损失等Log,直到到达规定输入的迭代次数。在训练完成后绘制损失-(迭代次数/画图精度)函数图像折线图,用于性能评估分析。
5、测试采样
输入(类别,姓名起始字母)对,返回生成的姓名。
五、结果分析与性能评价
PS: []中的为每一次迭代的最可能的字母前五,如果为空,就是已经到达迭代终点。
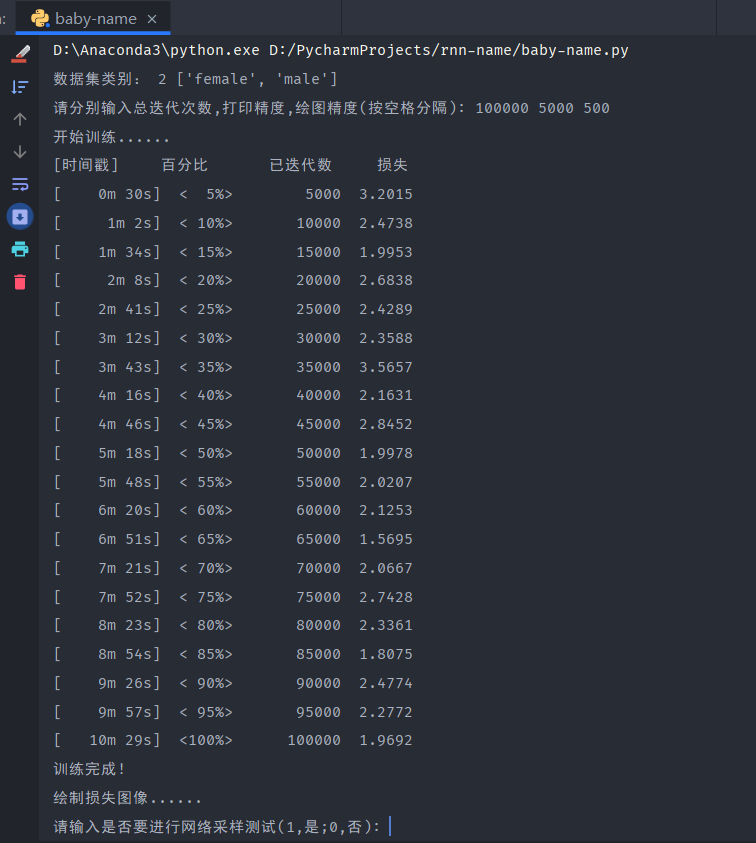
下面是100000次迭代的测试采样结果,可以发现生成的姓名非常好,完全符合日常的姓名样式,RNN神经网络性能很好。
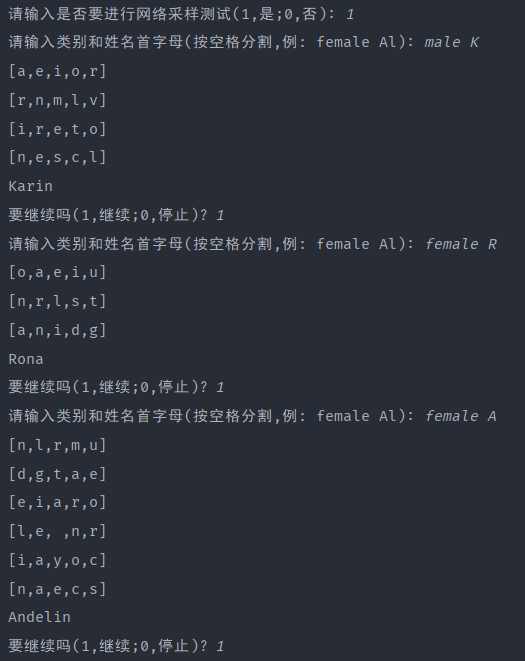
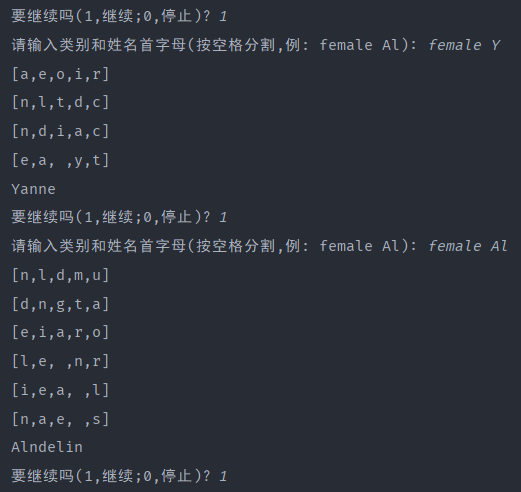
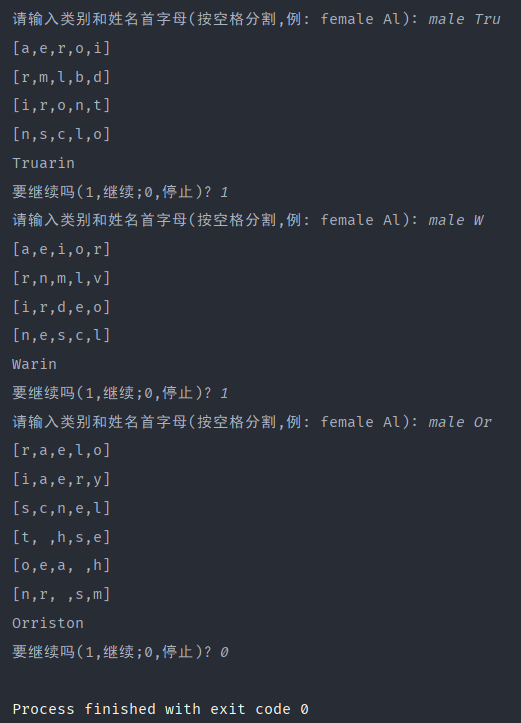
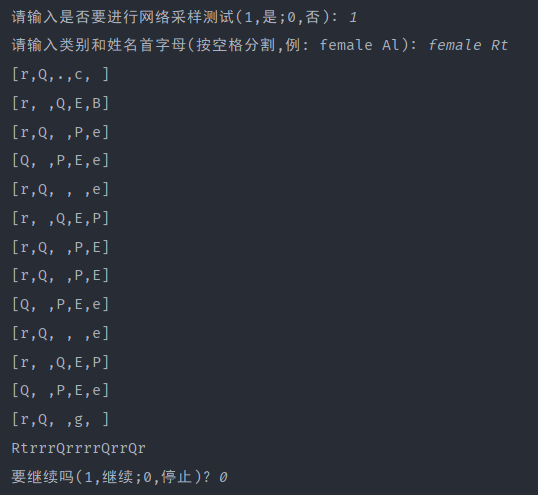
100次的因为迭代次数太少,网络非常不好,完全不能生成所需的姓名:
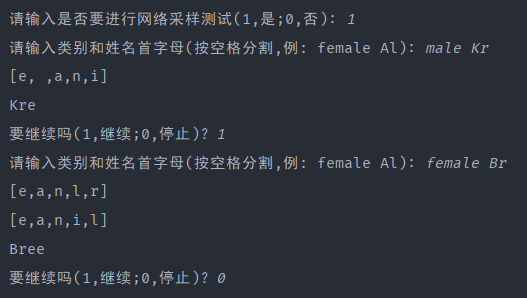
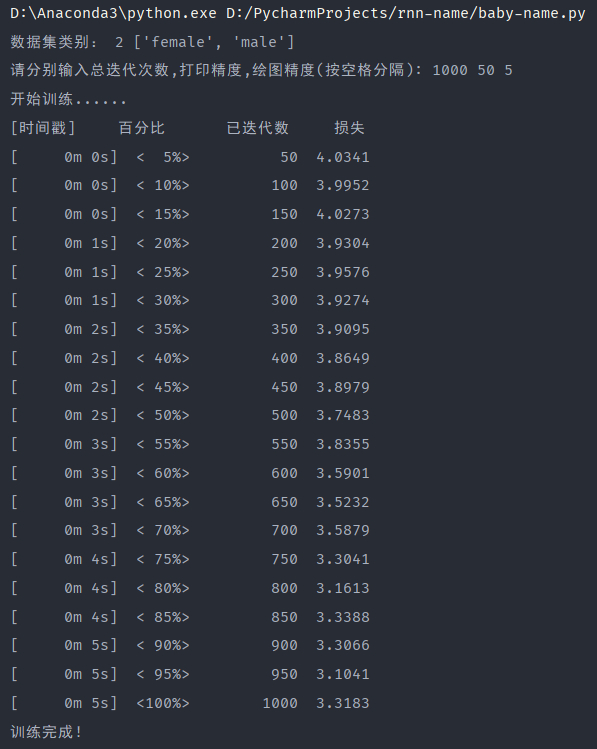
1000次还算可以接受:
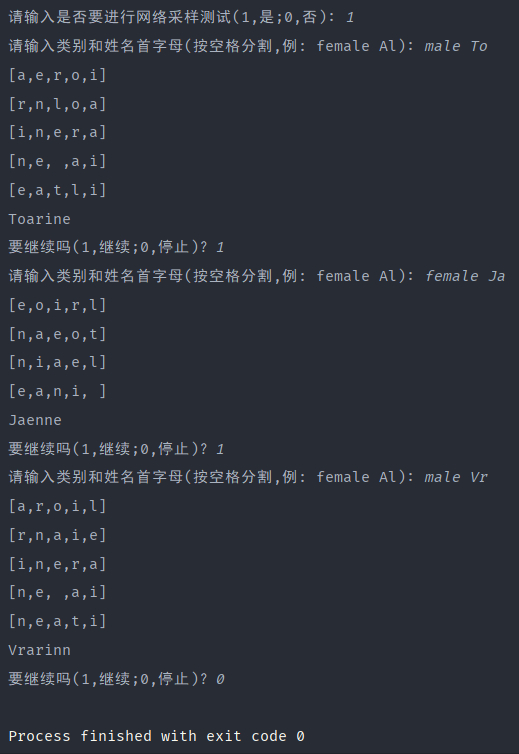
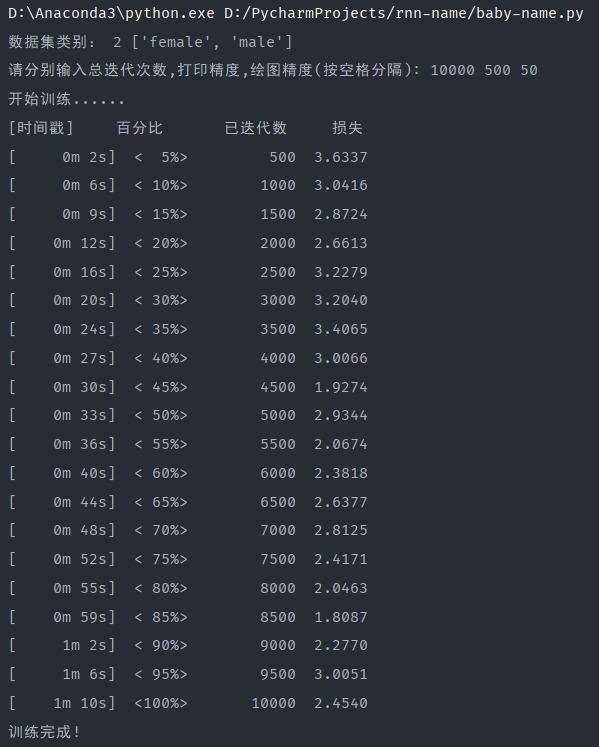
如果是10000次迭代,基本能满足生成姓名的要求:
观察并对比不同迭代次数的损失-(迭代次数/画图精度)函数折线图可以看出迭代次数越多损失越小,性能越好,且一开始损失下降较快,当迭代次数大到一定程度后,损失下降较慢。
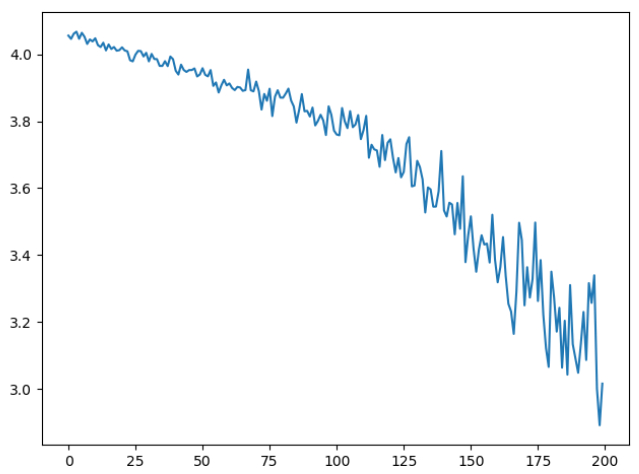
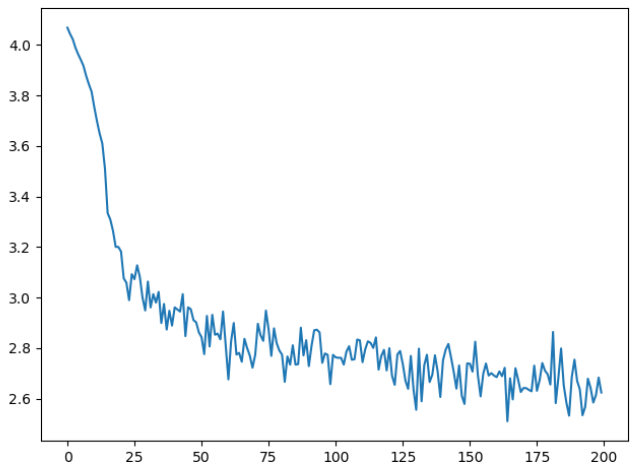
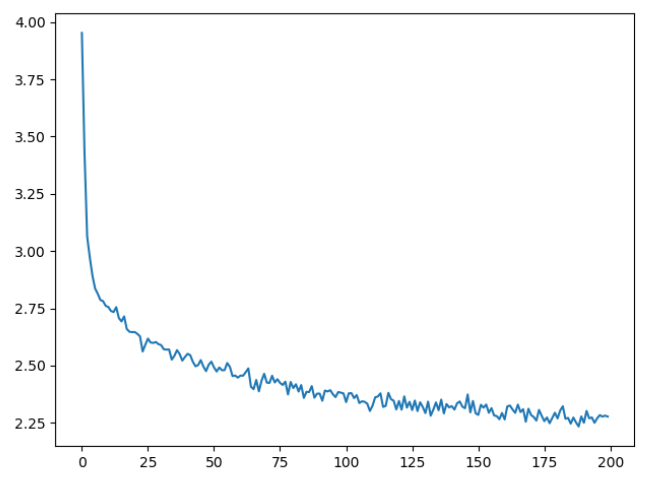
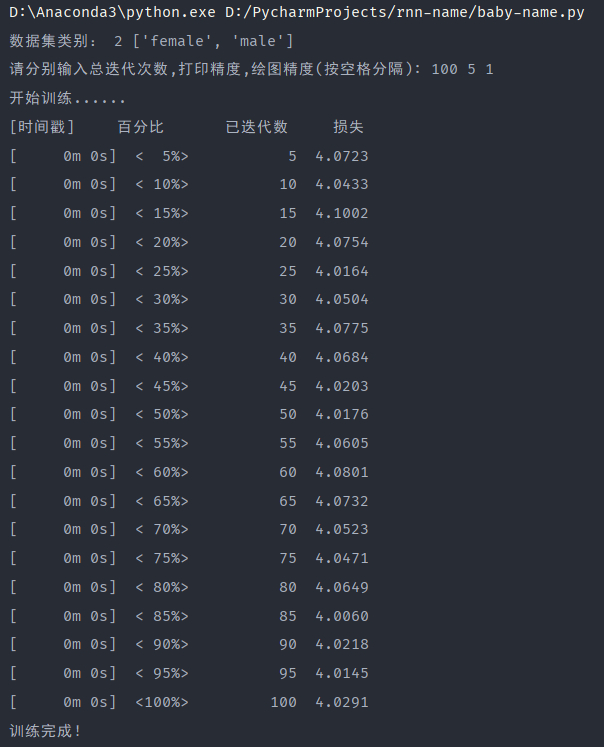
查看并对比不同迭代次数的损失日志输出,很明显能发现最大的区别就是训练时间。可以看出迭代次数越多花费时间越多,所需的电脑性能显然也需要更高,100次和1000次由于网络不好,可以先排除在外。100000次迭代的所需时间是10min左右,而10000次迭代所需的时间为1min左右,相差10倍,如果迭代次数更多,可能相差更多,因此选择合适的迭代次数很重要,避免不必要的性能时间浪费。
六、项目地址
本项目的源码、可执行程序均已经存放于我的Github,欢迎下载查看:
七、附录
点击查看代码
1 | from __future__ import unicode_literals, print_function, division |



本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议

