大数据实战 Spark Streaming 实时计算Kafka数据
本文是关于大数据通过Spark Streaming实现流计算Kafka数据进行单词计数。
一、实验环境:
- 虚拟机数量:3(一主两从,主机名分别为:master、slave01、slave02)
- 系统版本:Centos 7.5
- Zookeeper版本: Apache Zookeeper 3.4.10
- Kafka版本:kafka_2.11-0.10.2.1
- Spark版本:Apache Spark 2.1.1
二、实验内容:
- 通过创建Kafka topic,使用Kafka Producer产生消息,然后通过编写spark
Streaming程序处理这些消息。
- 主要步骤:
- 创建Spark Streaming项目工程
- 编写streaming程序
- 启动Zookeeper,Kafka集群
- 创建topic
- 启动Kafka生产者
- 准备作业环境
- 提交作业
三、实验步骤:
3.1打开IDEA软件
1
2
3
| cd
cd idea-IC-172.4574.19/
bin/idea.sh &
|

3.2创建项目
3.2.1创建同之前章节结构一致的项目spark_test, 设置语言级别为8。
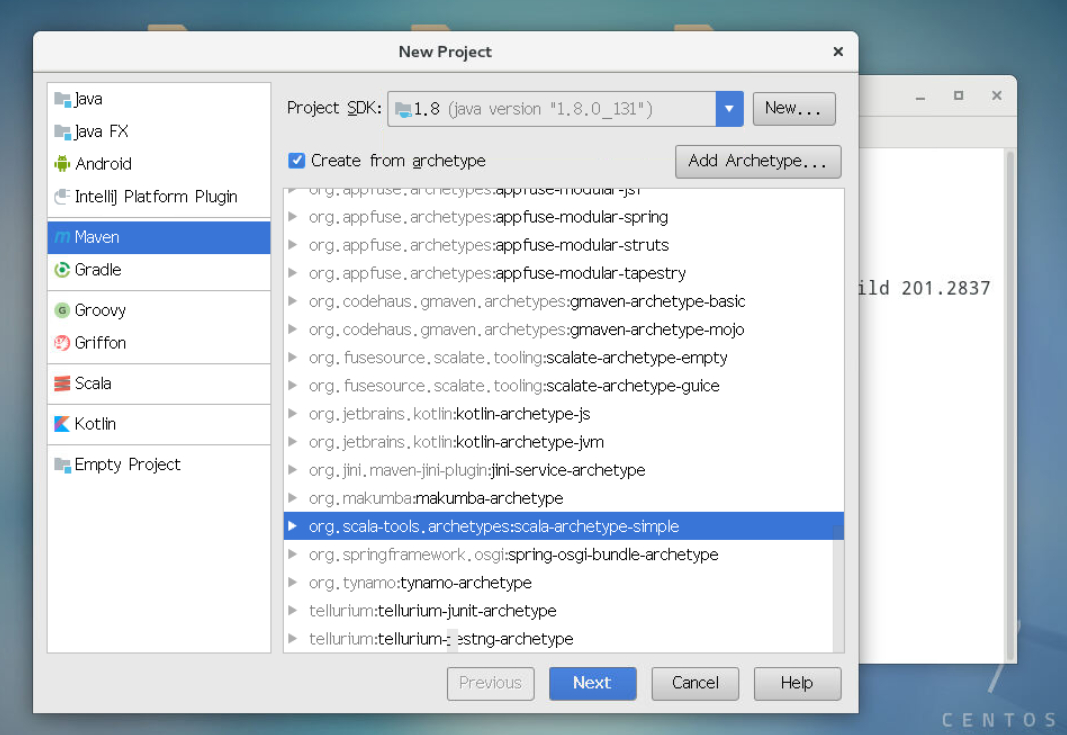
3.2.2点击 Create New Project,进入如下图界面,按照图标依次点击,最后点击next。
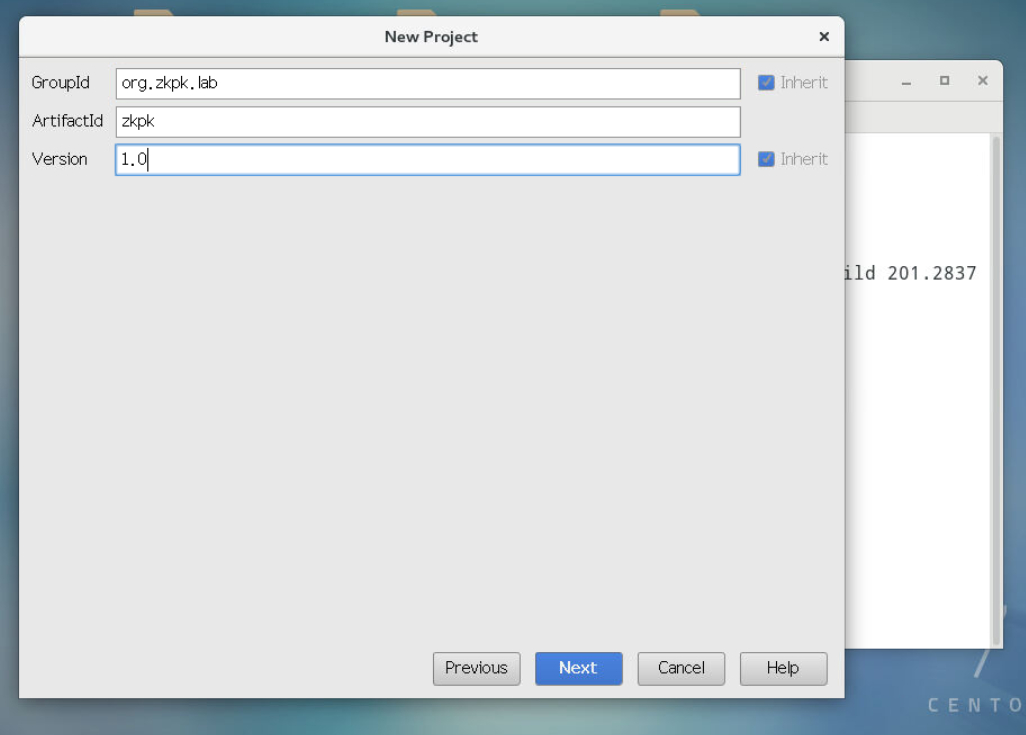
3.2.3依次输入GroupId和ArtifactId和Version的值,随后点击next。
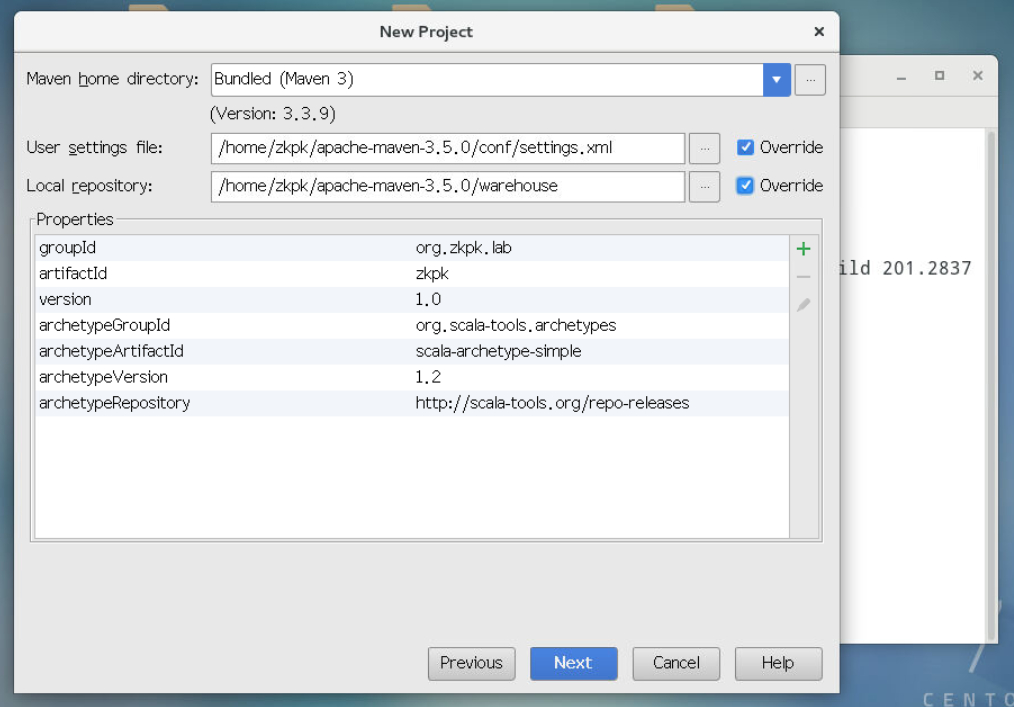
3.2.4进入如下界面,设置本地Maven项目的setting.xml文件和warehouse仓库,点击next按钮。
3.2.4.1本地setting.xml文件在/home/zkpk/apache-maven-3.5.0/conf目录下。
3.2.4.2本地仓库文件夹warehouse在/home/zkpk/apache-maven-3.5.0/warehouse。
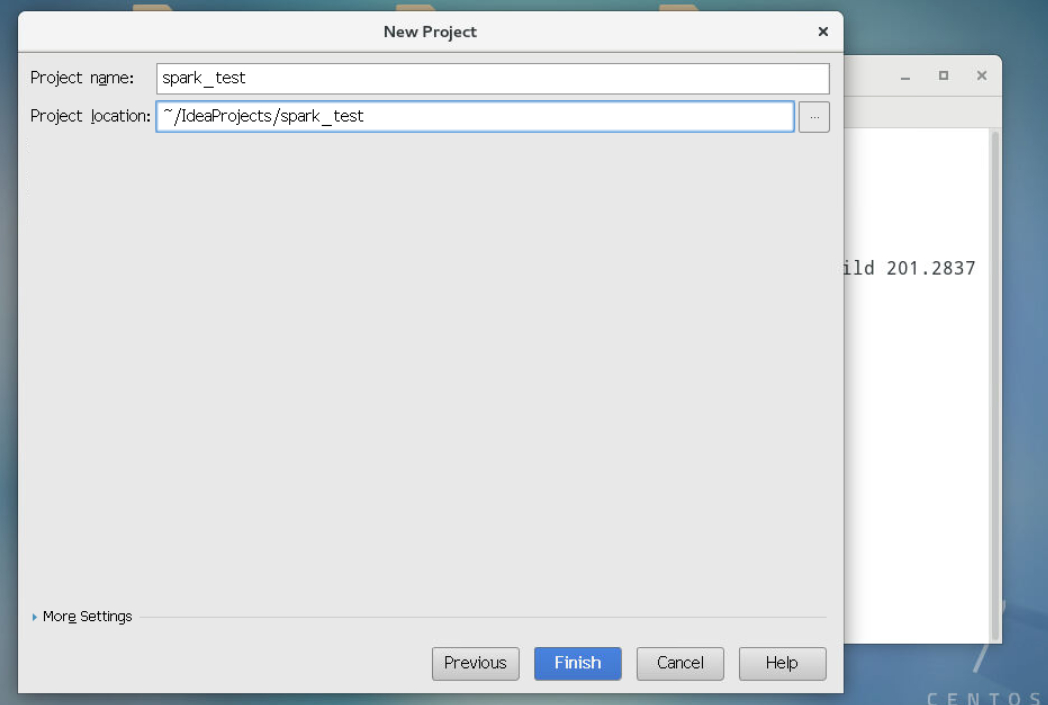
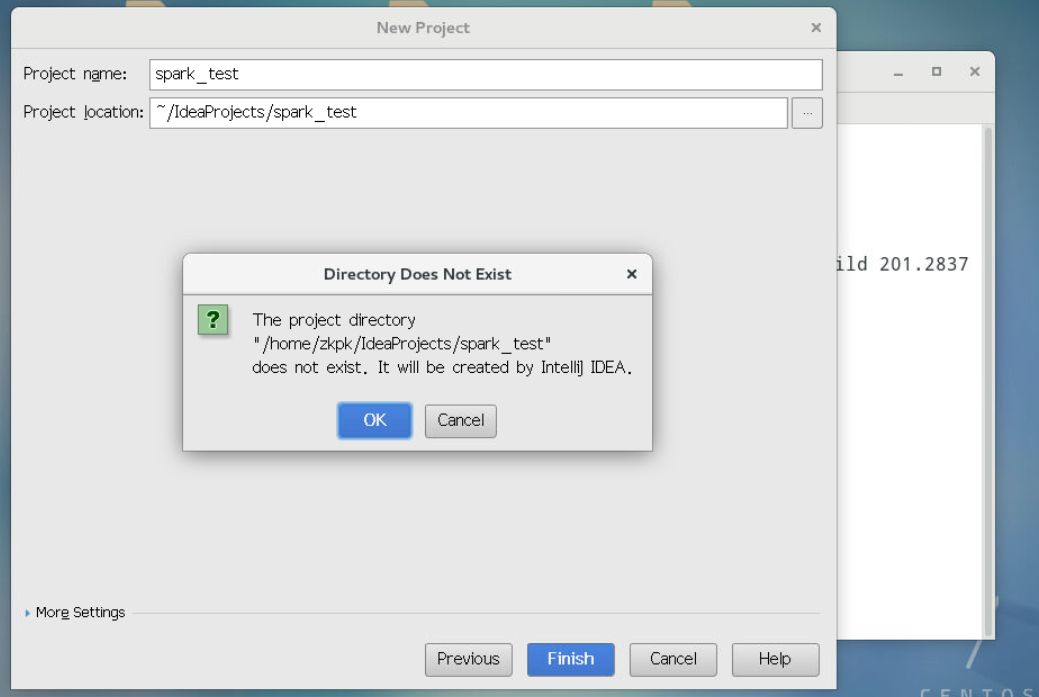
3.2.5进入如下界面,输入工程名称spark_test,然后点击next,OK。
3.2.6工程创建完成后会自动打开一个名为zkpk的xml文件,按照以下修改:
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.zkpk.lab</groupId>
<artifactId>zkpk</artifactId>
<version>1.0</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.11</scala.version>
<spark.version>2.1.1</spark.version>
<hadoop.version>2.7.3</hadoop.version>
<kafka.version>0.10.2.1</kafka.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
|
3.2.7保存修改的pom.xml文件后,点击工程名,依次选择Maven——>Reimport,即可根据pom.xml文件导入依赖包。
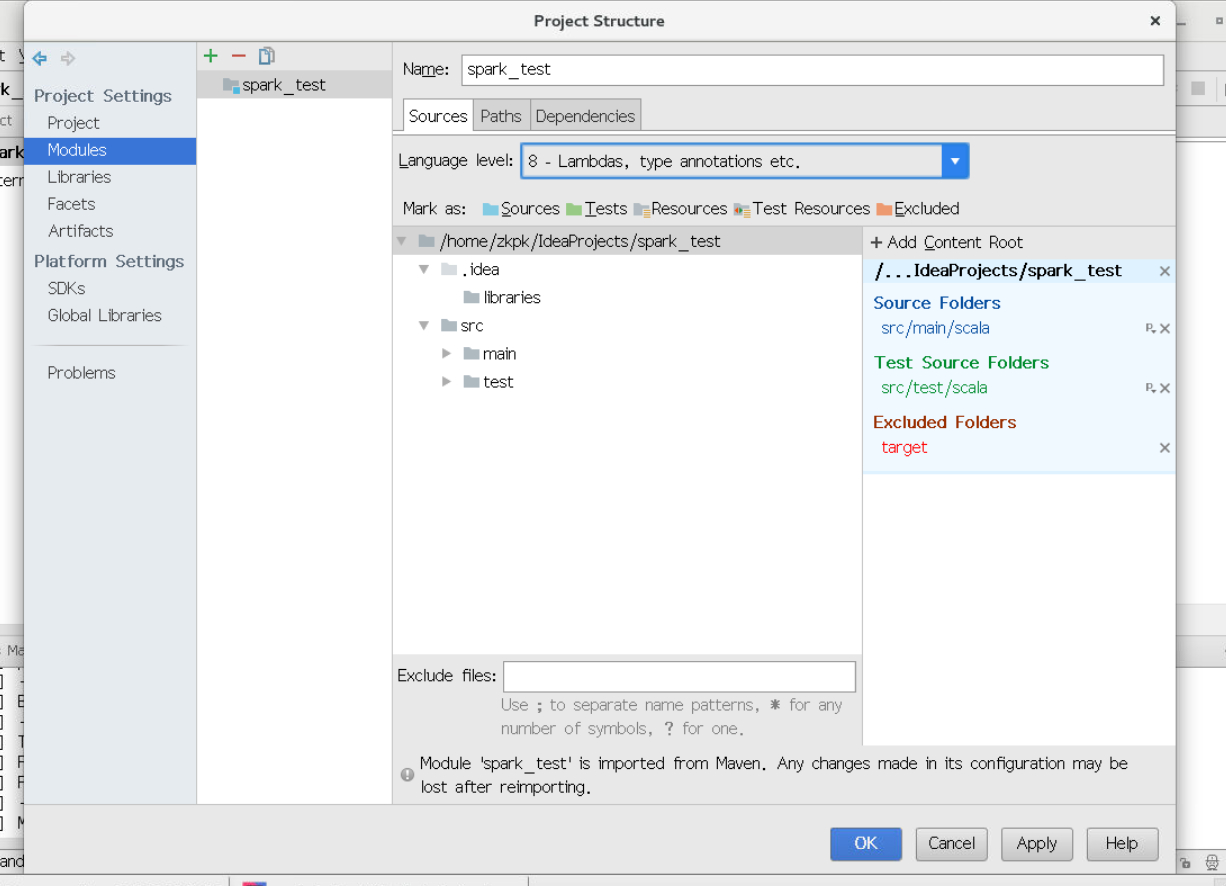
3.2.8设置语言环境language level,点击菜单栏中的file,选择Project Structure,弹出如下对话框,选择Modules,选择Language level为8,然后点击Apply,点击OK。
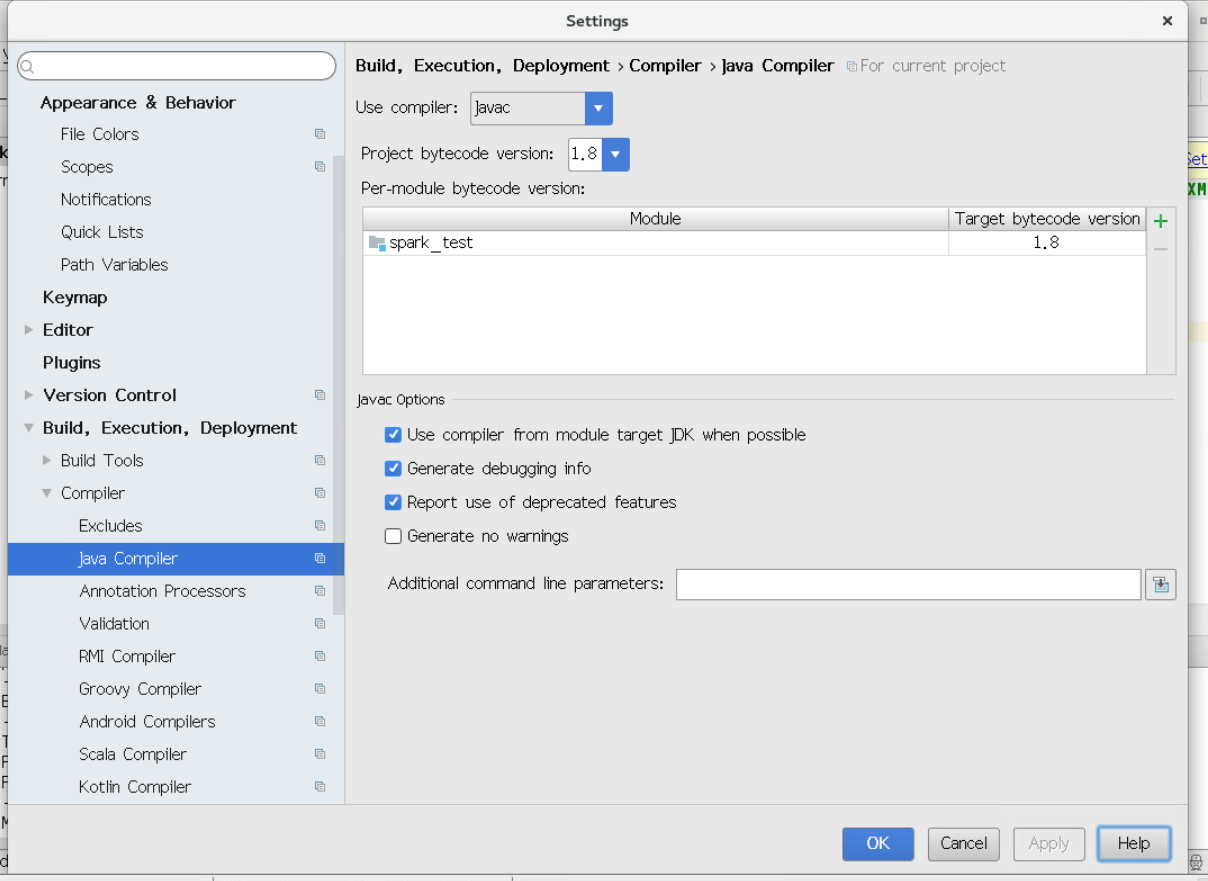
3.2.9设置Java Compiler环境,点击菜单栏中的file,选择Setting,弹出如下对话框,依次选择Build,Execution——>Compiler——>Java Compiler,设置图中的Project bytecode version为1.8,设置图中的Target bytecode version为1.8,然后依次点击Apply和OK。
至此,Spark Maven工程创建完毕。
3.2.10在项目sclaa文件下的org.zkpk.lab下新建“kafka_streaming”Object。
创建完成后的工程结构:
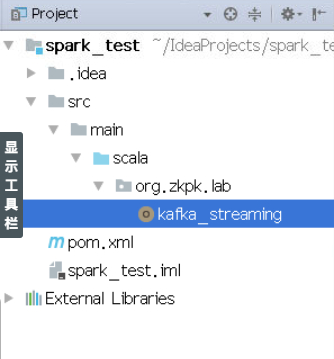
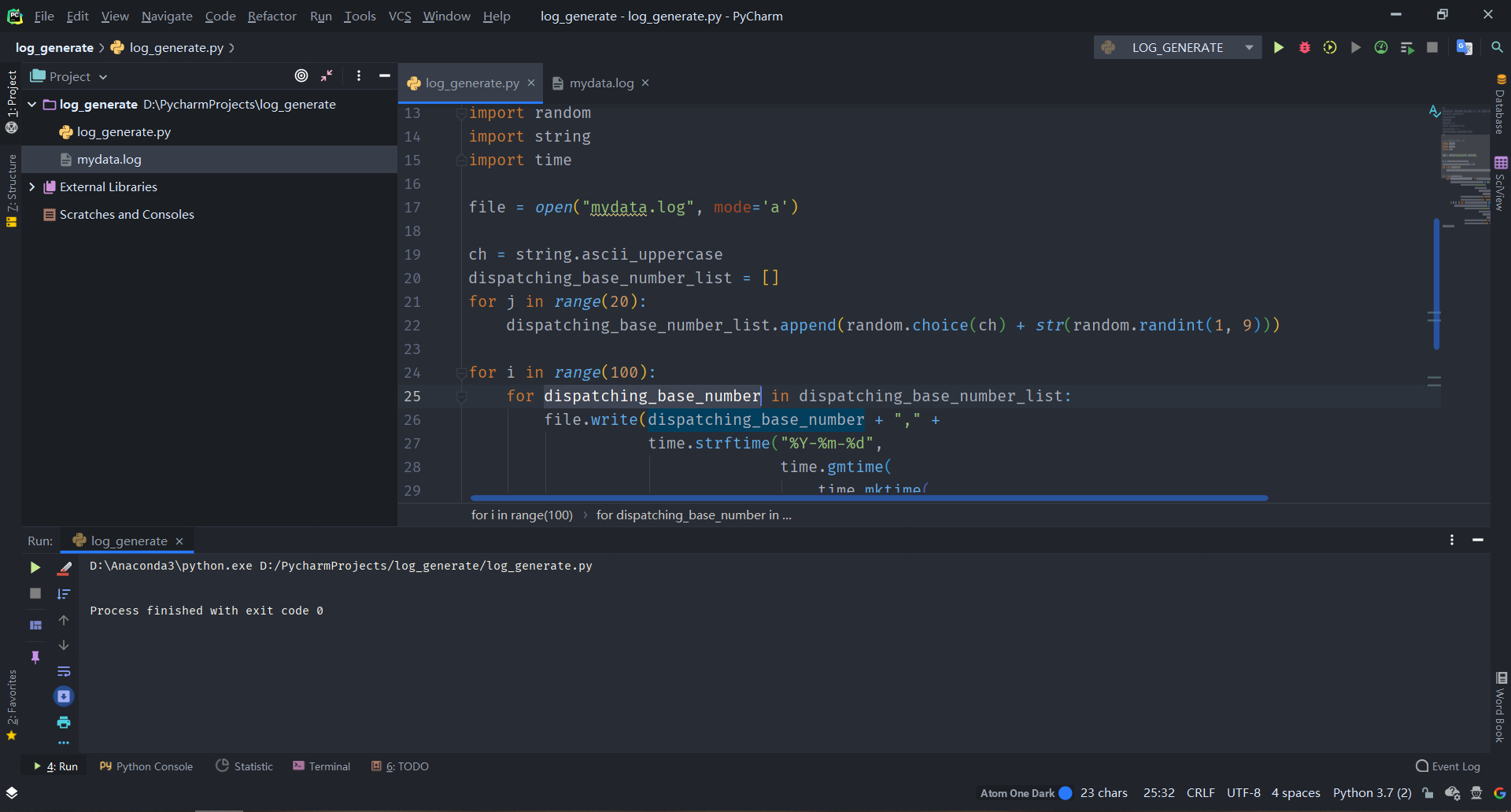
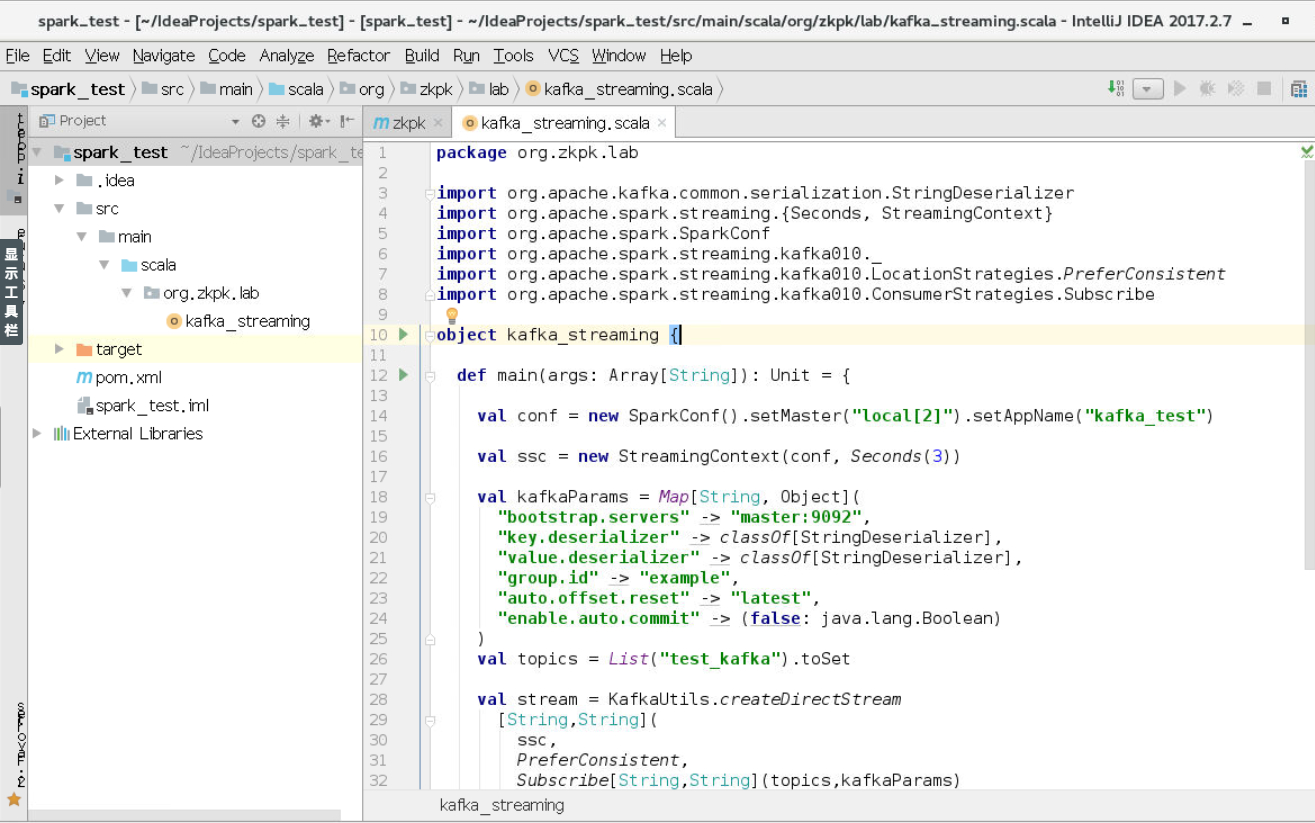
3.3编写scala代码
下面是部分代码截图,具体代码在本文的附录中。
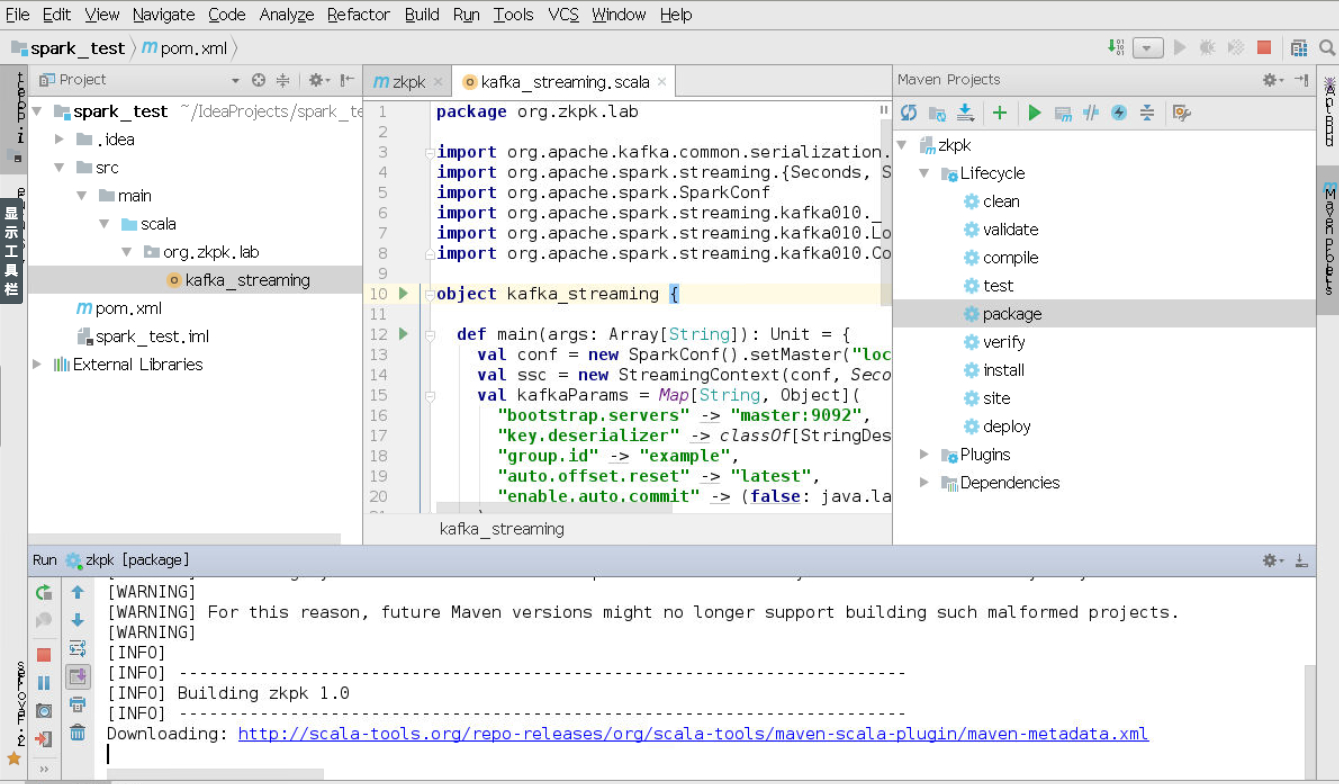
3.4使用maven打包程序
开始打包。
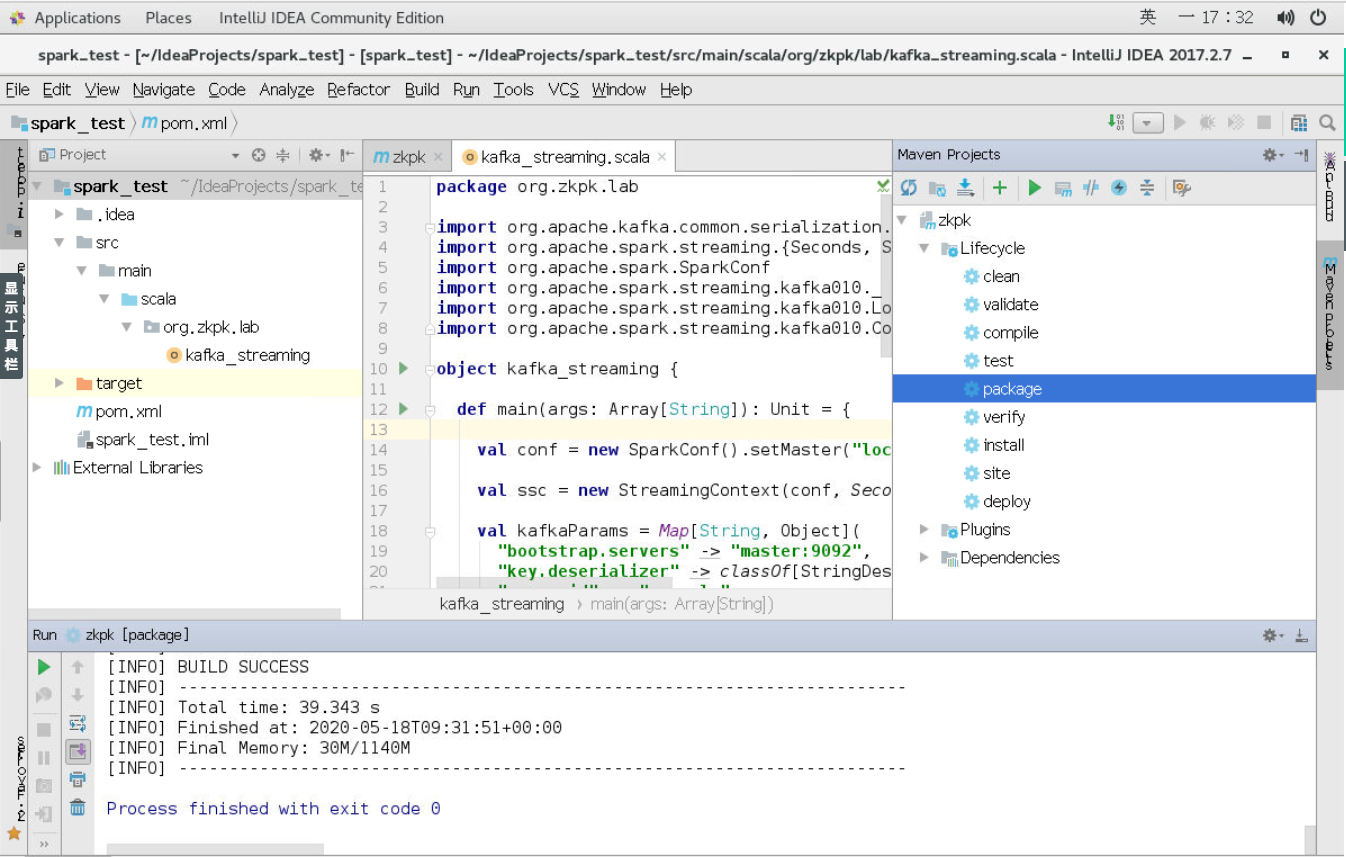
打包完成。
3.5启动Zookeeper集群
3.5.1分别登录master和slave01、slave02节点,进入zookeeper安装目录,启动服务。
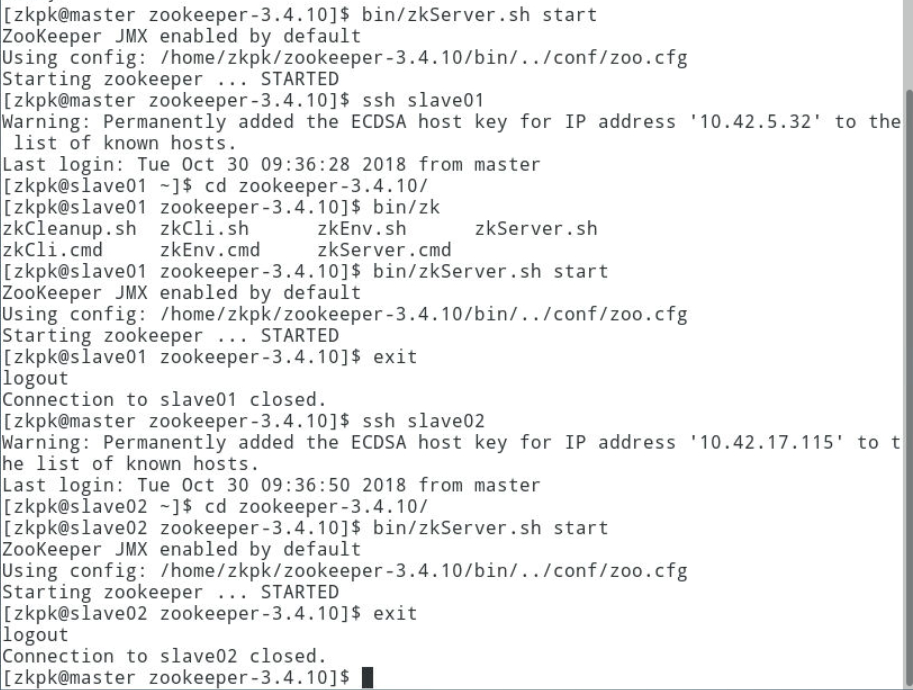
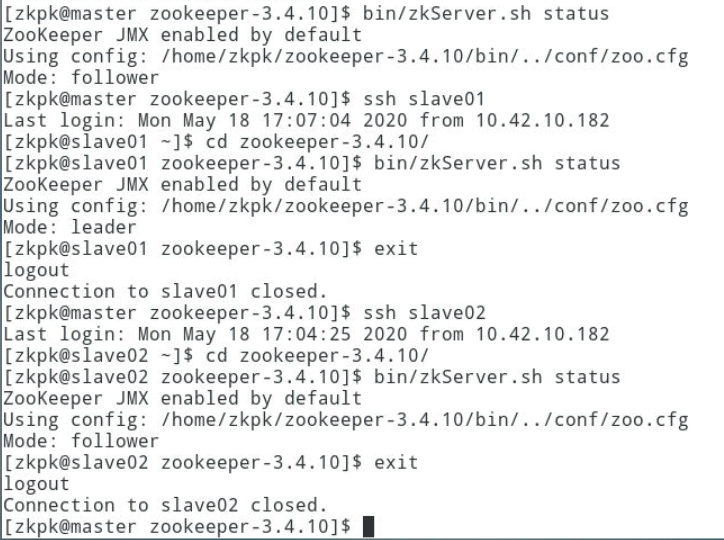
3.5.2在三个节点上分别运行bin/zkServer.sh status命令查看状态,出现follower或leader表示ZK启动成功。
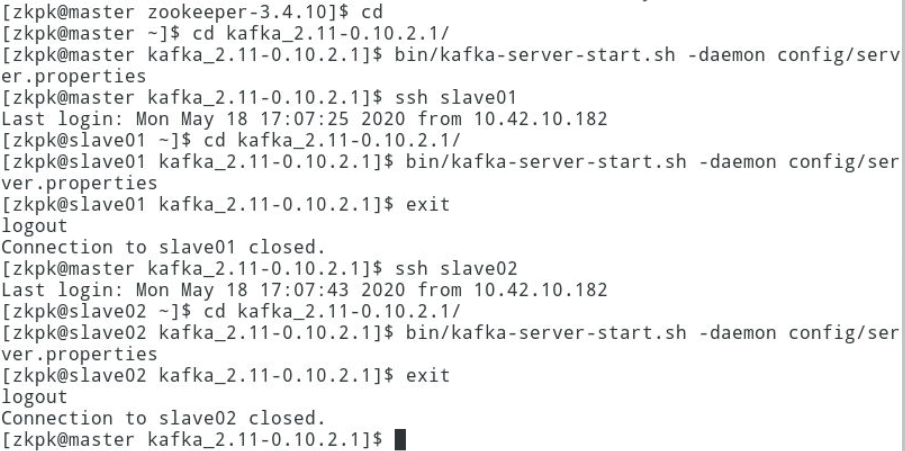
3.6启动Kafka集群
在 master 和 slave01、slave02节点分别启动 Kafka。
3.7创建Kafka topic
名称需要和代码中保持一致。

3.8在一个终端上启动一个生产者,准备生产

3.9使用spark-submit提交spark 应用
3.9.1将生成的jar包文件复制到/home/zkpk下。

3.9.2提交sparkjob之前需要将spark-streaming-kafka-0-10_2.11-2.1.0,kafka-clients-0.10.2.这两个jar添加到spark_home/jars/路径下,否则程序提交会报错。

3.9.3新开一个终端,在/home/zkpk目录下提交程序。
1
| spark-submit --class org.zkpk.lab.kafka_streaming zkpk-1.0.jar
|
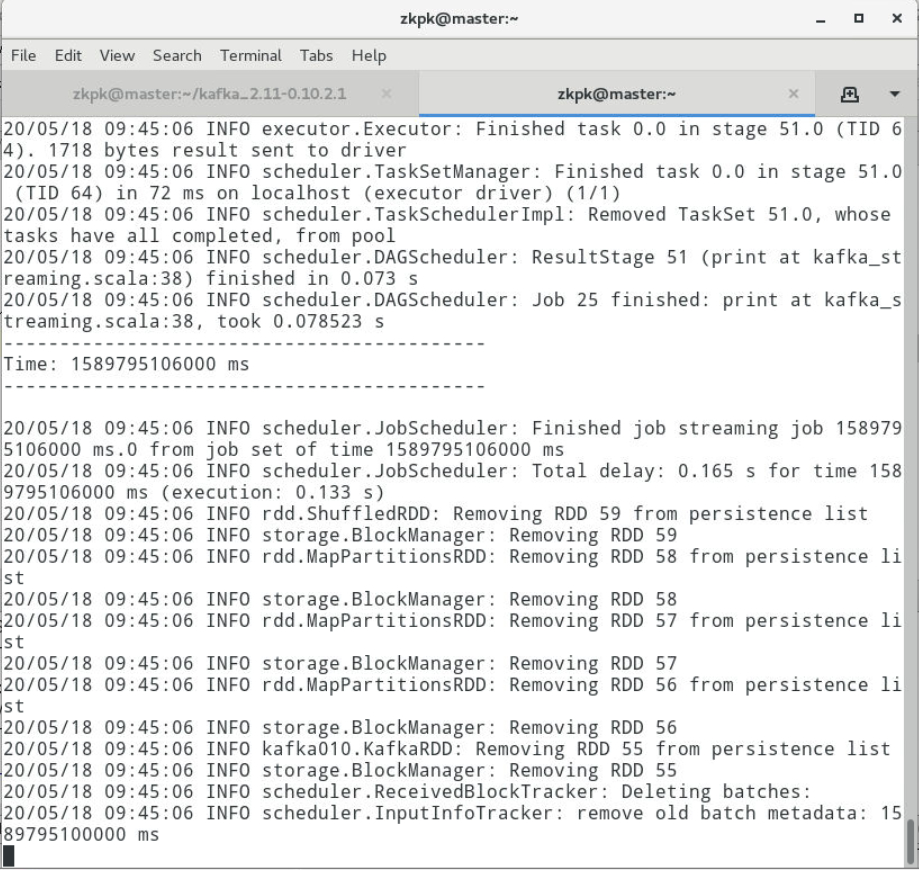
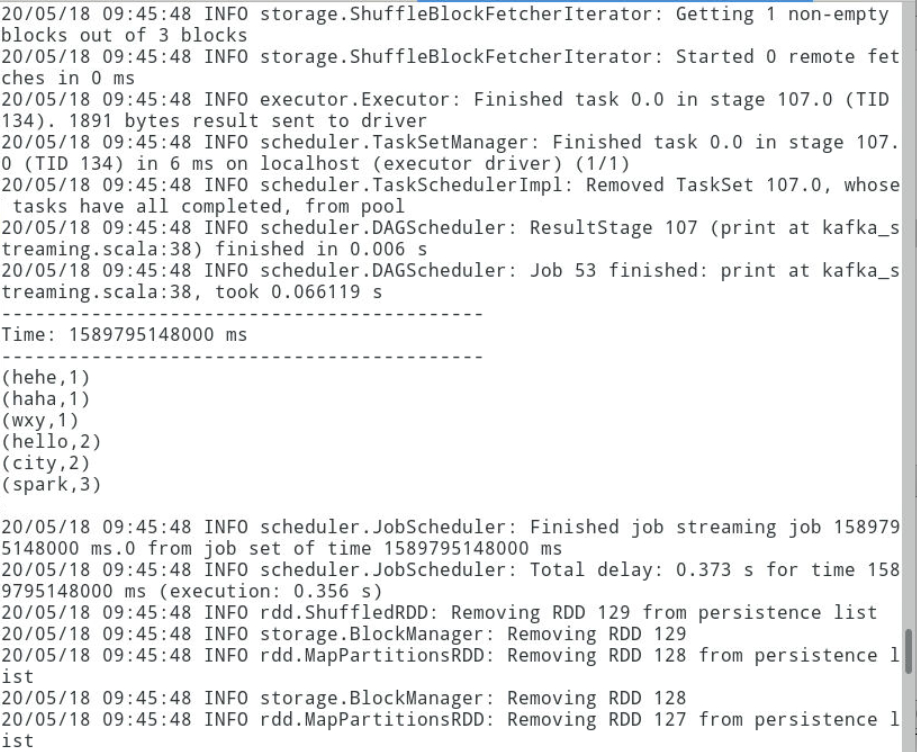
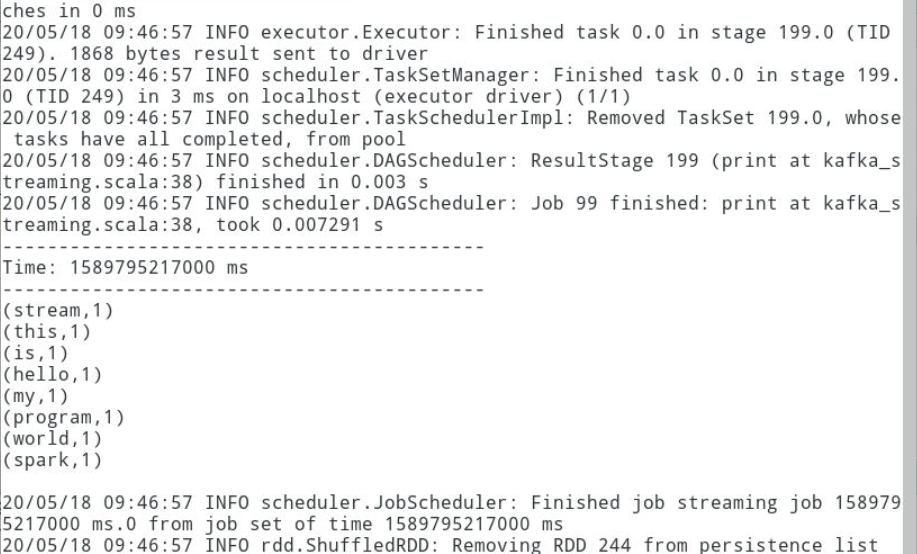
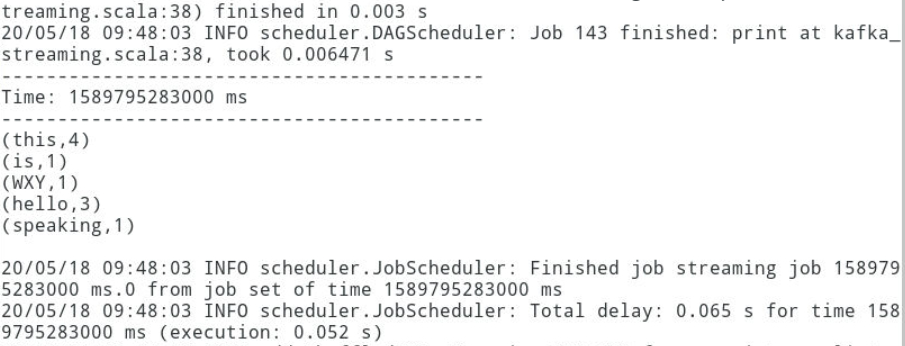
3.10输入内容,查看结果
切换到之前的Kafka生产者终端中输入如下内容,然后切换到sparkStreaming任务界面查看结果。
四、附录
kafka_streaming.scala
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| package org.zkpk.lab
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object kafka_streaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("kafka_test")
val ssc = new StreamingContext(conf, Seconds(3))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "master:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "example",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = List("test_kafka").toSet
val stream = KafkaUtils.createDirectStream
[String,String](
ssc,
PreferConsistent,
Subscribe[String,String](topics,kafkaParams)
)
val lines = stream.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordcounts = words.map((_,1)).reduceByKey(_+_)
wordcounts.print()
ssc.start()
ssc.awaitTermination()
}
}
|