







Linux 上机实战1 正则表达式
本文是关于Linux中的文本处理三剑客(grep,sed,awk),以及正则表达式应用的一个样例,获取北京某时刻PM2.5的数据,然后进行处理,输出到csv文件中,并画图表展示。
一、题目要求:
从因特网上搜索 Web 页,用 wget 获取网页,处理网页 html 文本数据,从中提取出当前时间点北京各监测站的 PM2.5 浓度,输出如下 CSV 格式数据:
2020 03 09 13:00:00, 海淀区万柳 ,73
2020 03 09 13:00:00, 昌平镇 ,67
2020 03 09 13:00:00, 奥体中心 ,66
2020 03 09 13:00:00, 海淀区万柳 ,73
2020 03 09 13:00:00, 昌平镇 ,73
2020 03 09 13:00:00, 奥体中心 ,75
撰写实验报告,要求:写出对数据的分析和处理思路,列出各个处理步骤并给出解释。
二、详细步骤:
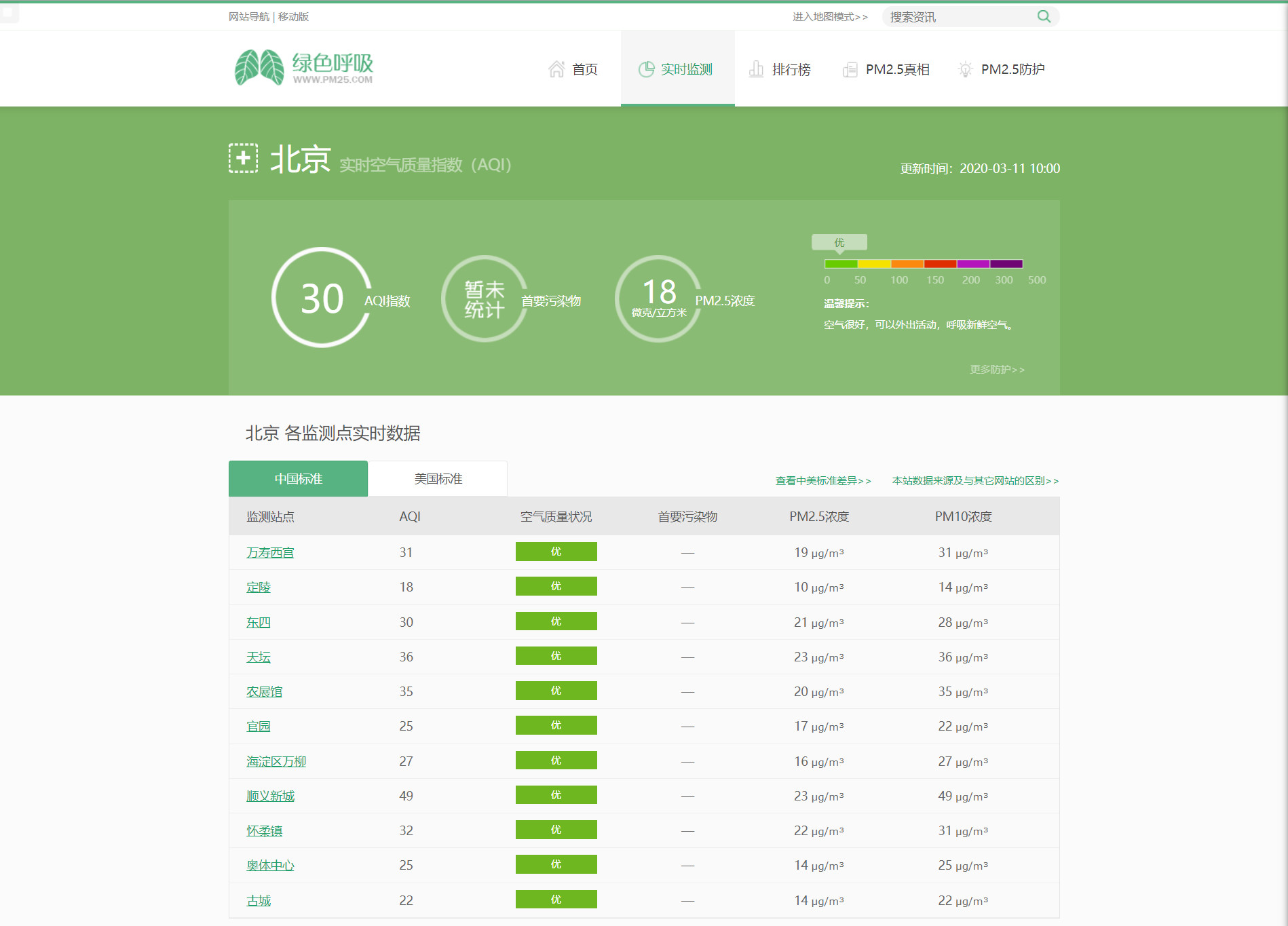
从因特网上搜索 Web 页,找到与含有北京各监测站的 PM2.5 浓度的网站,我找到了**绿色呼吸网**,网站如下:
使用**Xshell**登录到Ubuntu服务器:
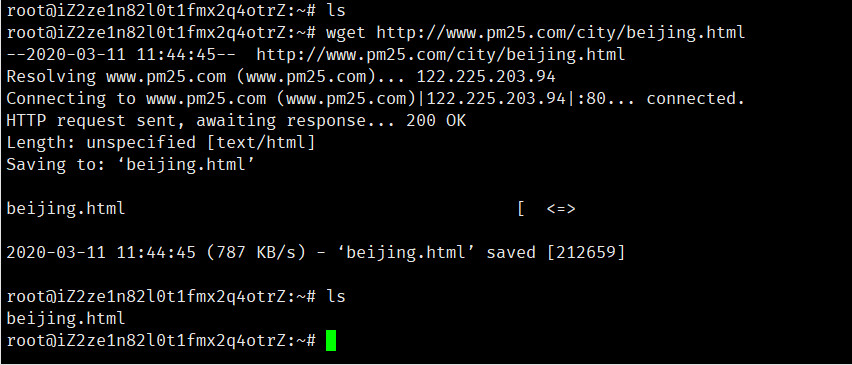
使用**wget**命令获取该网页:
1
wget http://www.pm25.com/city/beijing.html
使用**cat**命令查看该网页的内容:
1
cat beijing.html | more
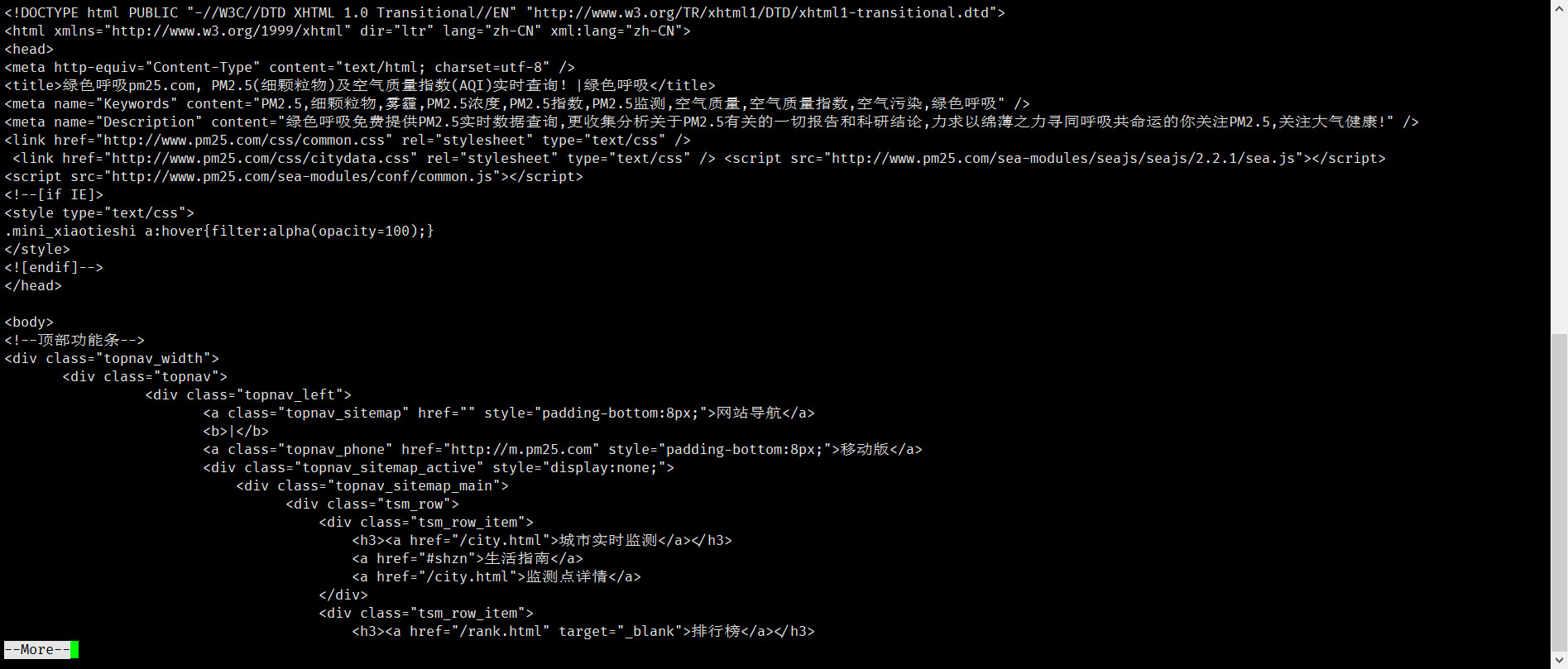
我们关注的内容:
①数据更新的时间:

②各监测点PM2.5浓度数据:
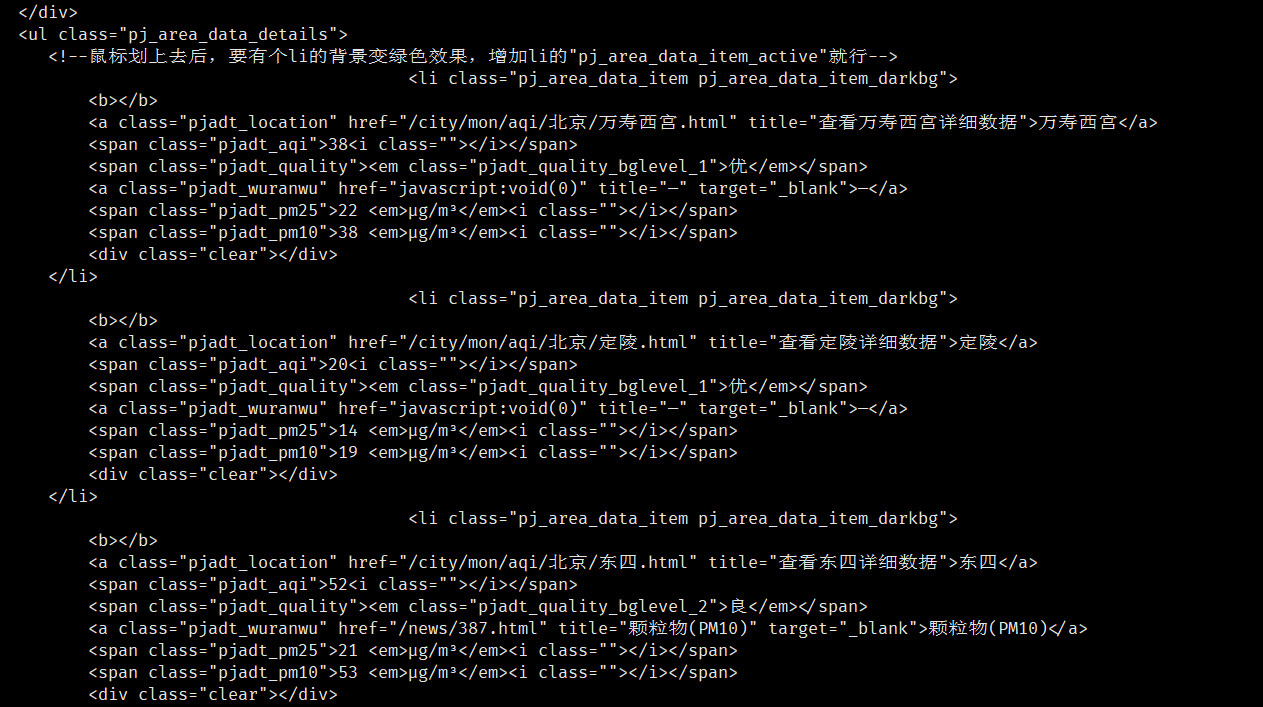
发现时间的地方有个*“更新时间:”**,监测点名称的地方都有“pjadt_location”*,而PM2.5浓度的地方都有**“pjadt_pm25”。根据这个特性,先使用*awk**命令将需要的行保留下来。下面先进行编写1.awk***:
1
vim 1.awk
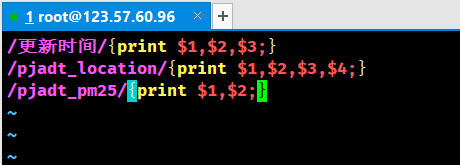
运行以下命令,对所需行进行过滤:
1
cat beijing.html | awk -f 1.awk | more
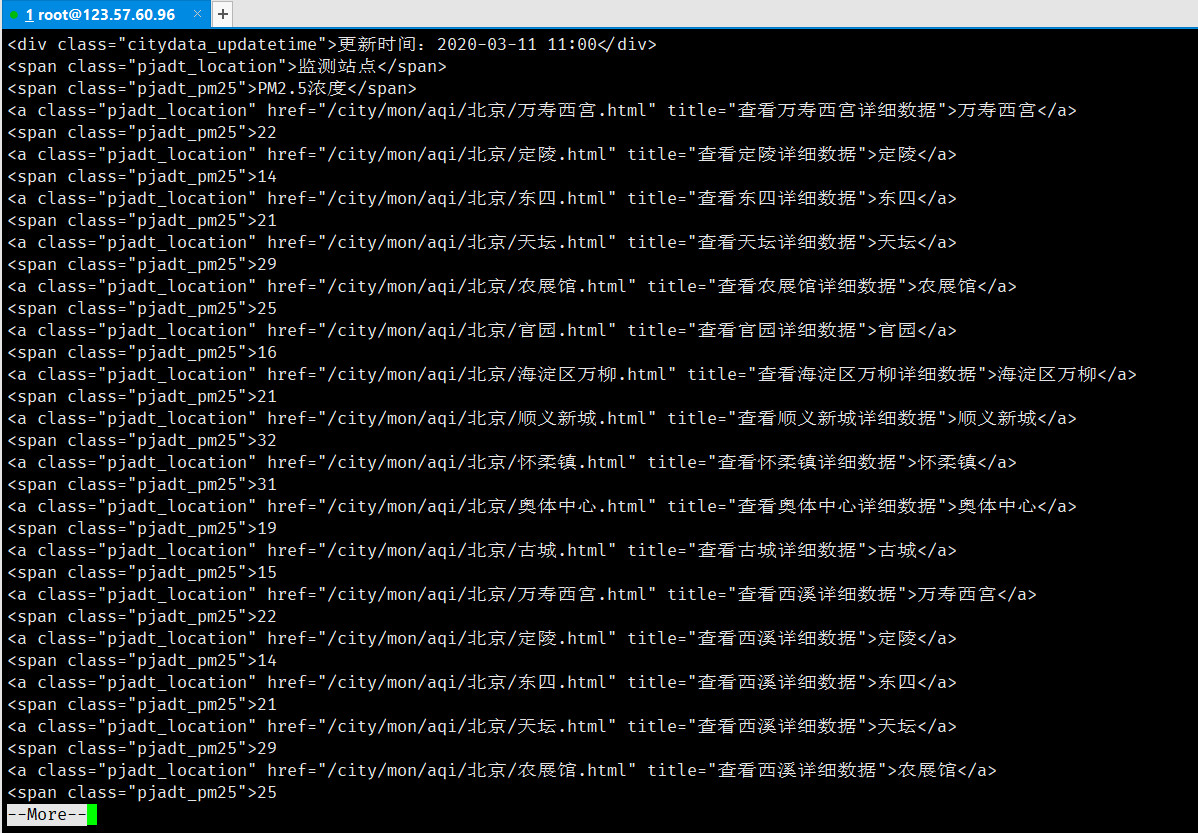
发现除了我们想要的行还多出了这几行:

经过观察,发现*“PM2.5”**浓度这一行与我们所需的行的区别是,我们所需的行有μg*,而**“PM2.5”浓度这一行没有:

我们重新对*“1.awk”**进行编辑,直接将“监测站点”*这一行排除,并且对**“PM2.5”浓度这一行采用额外的过滤规则:
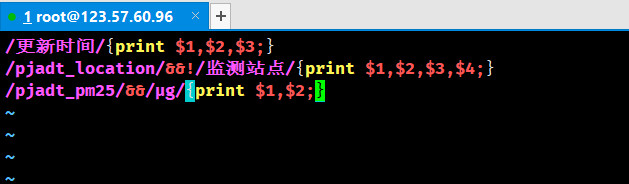
重新运行以下命令,对所需行进行过滤:
1
cat beijing.html | awk -f 1.awk | more
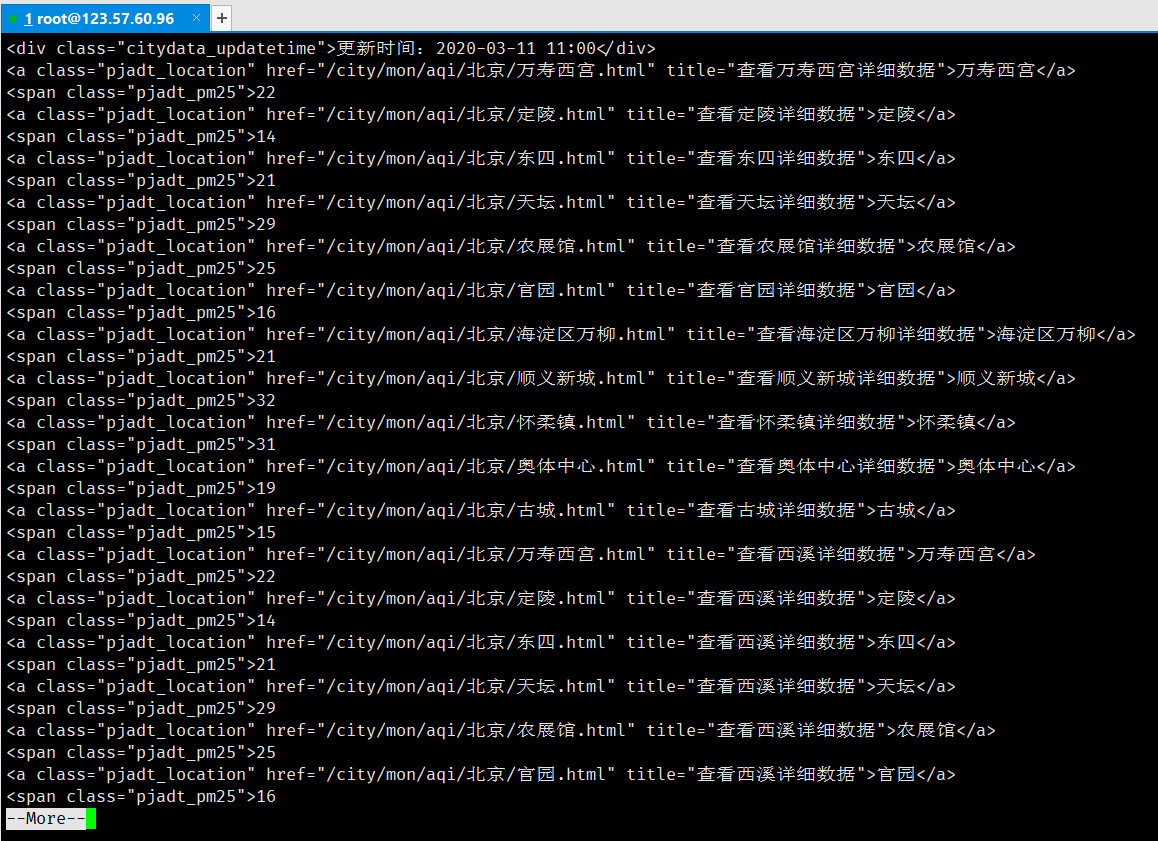
发现已经筛选出了所需要的行。
现在再利用*sed**命令将html标签”<>“*中的内容和**“更新时间:”这个无用的信息删除:
1
cat beijing.html | awk -f 1.awk | sed -e 's/<[^<>]*>//g' -e 's/更新时间://g' | more
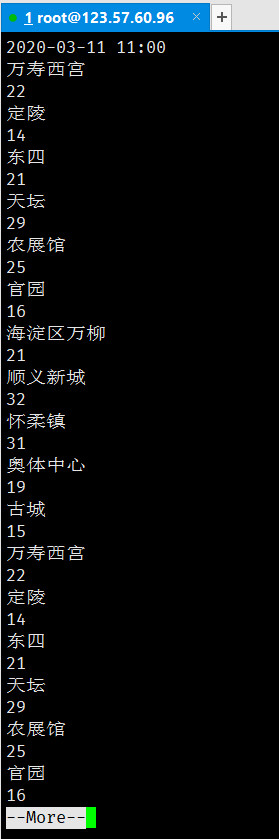
发现已经只剩余我们想要的数据。
但是这些数据不在同一行,且没有明显特征,无法进行*awk**命令,因此先使用tr***命令将这些行合并为一行,以空格分隔:
1
cat beijing.html | awk -f 1.awk | sed -e 's/<[^<>]*>//g' -e 's/更新时间://g' | tr '\n' ' ' | more

最后利用*awk**命令将所需内容规格化输出即可,先编辑“2.awk”***:
1
vim 2.awk
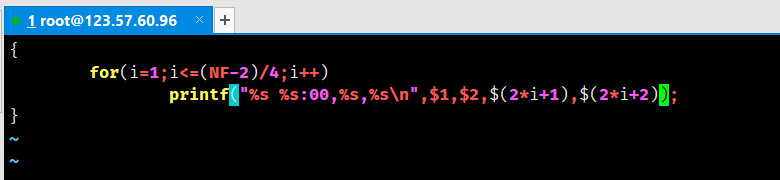
利用*for**循环输出,NF*为列数,刚好循环$$(NF-2)/4$$次,第一个**%s为*日期**,第二个%s*为**时间,第三个*%s**为监测点名称*,第四个**%s为*PM2.5浓度**,再运行以下awk***命令,即可得到格式化的输出:
1
cat beijing.html | awk -f 1.awk | sed -e 's/<[^<>]*>//g' -e 's/更新时间://g' | tr '\n' ' ' | awk -f 2.awk | more

发现输出已经符合题目要求。
将结果重定向到文件**“beijing.csv”**:
1
2cat beijing.html | awk -f 1.awk | sed -e 's/<[^<>]*>//g' -e 's/更新时间://g' | tr '\n' ' ' | awk -f 2.awk > beijing.csv
vim beijing.csv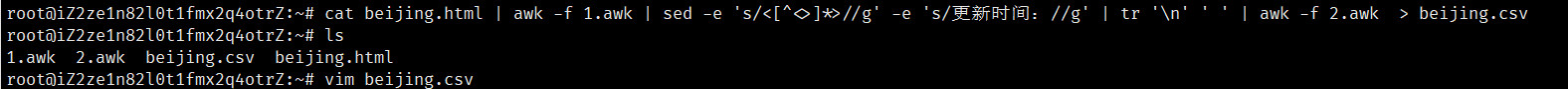
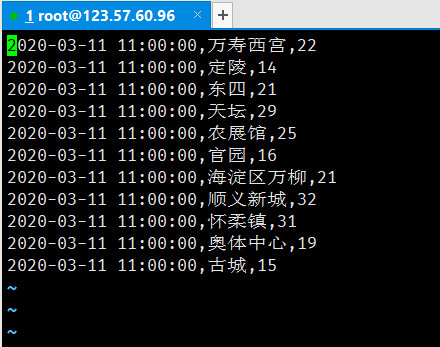
将*beijing.csv**发送到电脑,并将编码转为ANSI***:
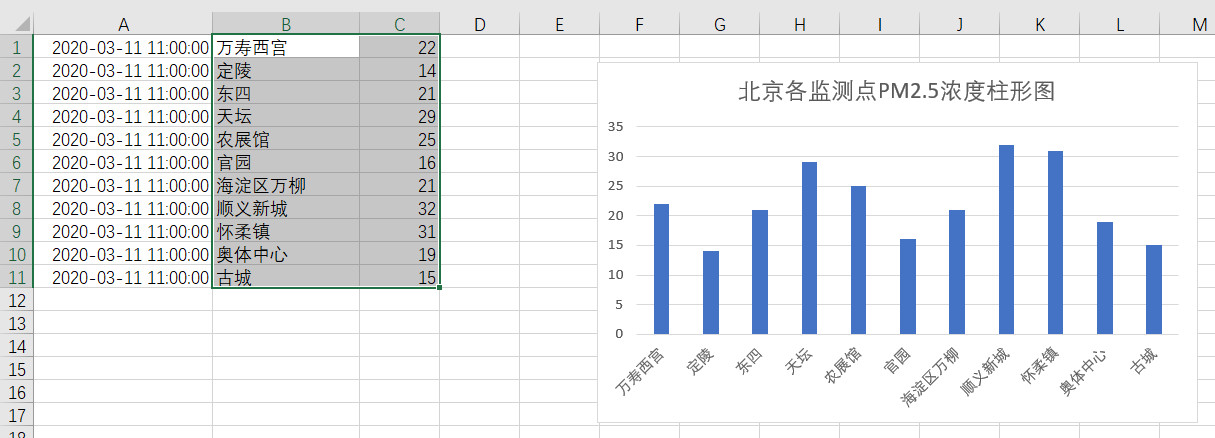
由于不同时间的数据有所不同,因此我的过滤语句考虑了不同时间点的情况*(北京一共有12个监测点,有时有的监测点没有数据,因此是只有11个监测点的数据)**,直接运行以下命令就可以直接将数据导出为beijing.csv***,以下为另一时间点的数据情况:
1
2wget http://www.pm25.com/city/beijing.html
cat beijing.html | awk -f 1.awk | sed -e 's/<[^<>]*>//g' -e 's/更新时间://g' | tr '\n' ' ' | awk -f 2.awk > beijing.csv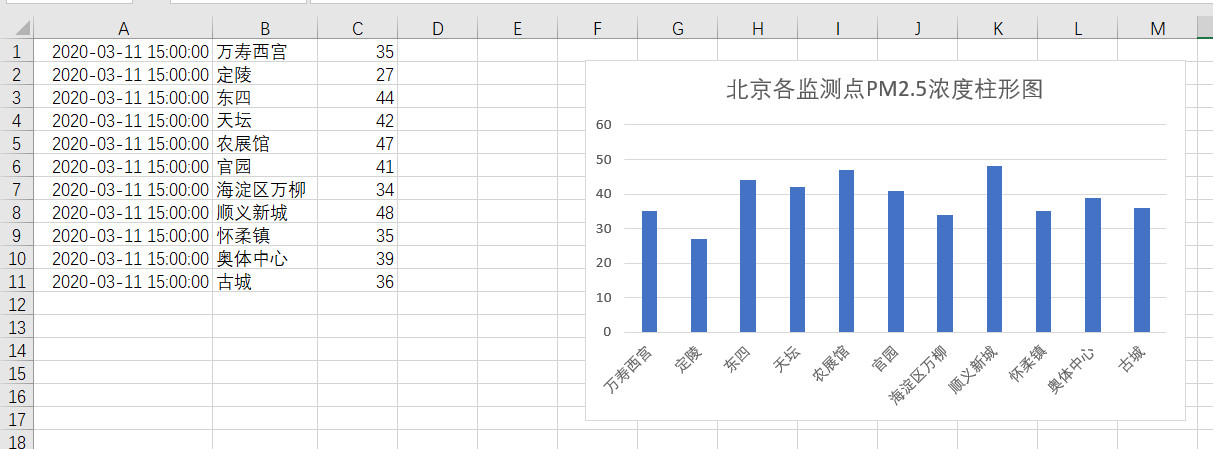
三、总结
本文以一个样例,详细介绍了Linux中的文本处理三剑客(grep,sed,awk),以及正则表达式的相关知识,希望对你的Linux学习有所帮助。
本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议

