本文是关于大数据通过Java进行Spark编程实现自选日志处理分析。
一、实验环境:
- 虚拟机数量:1
- 系统版本:Centos 7.5
- Spark版本:Apache Spark 2.1.1
- Eclipse版本:Neno.3 (4.6.3)
二、实验内容:
- 收集一组自选日志,构造mydata.log数据集,上传到实验环境中,重新完成对自选日志分析。
三、主要步骤:
- 获取自选数据集
- 自选数据集计算的需求分析
- 编程设计实现
- 运行程序
四、实验步骤:
4.1获取自选数据集以及数据字段格式解释说明
我受到平台的第一个实验和uber日志文件的启发,想到了自己用python生成uber日志文件,首先是日志的格式:
| 字段 |
数据类型 |
说明信息 |
| dispatching_base_number |
String |
区域编号 |
| date |
String |
日期 |
| active_vehicles |
int |
使用的机动车数量 |
| trips |
int |
旅游次数 |
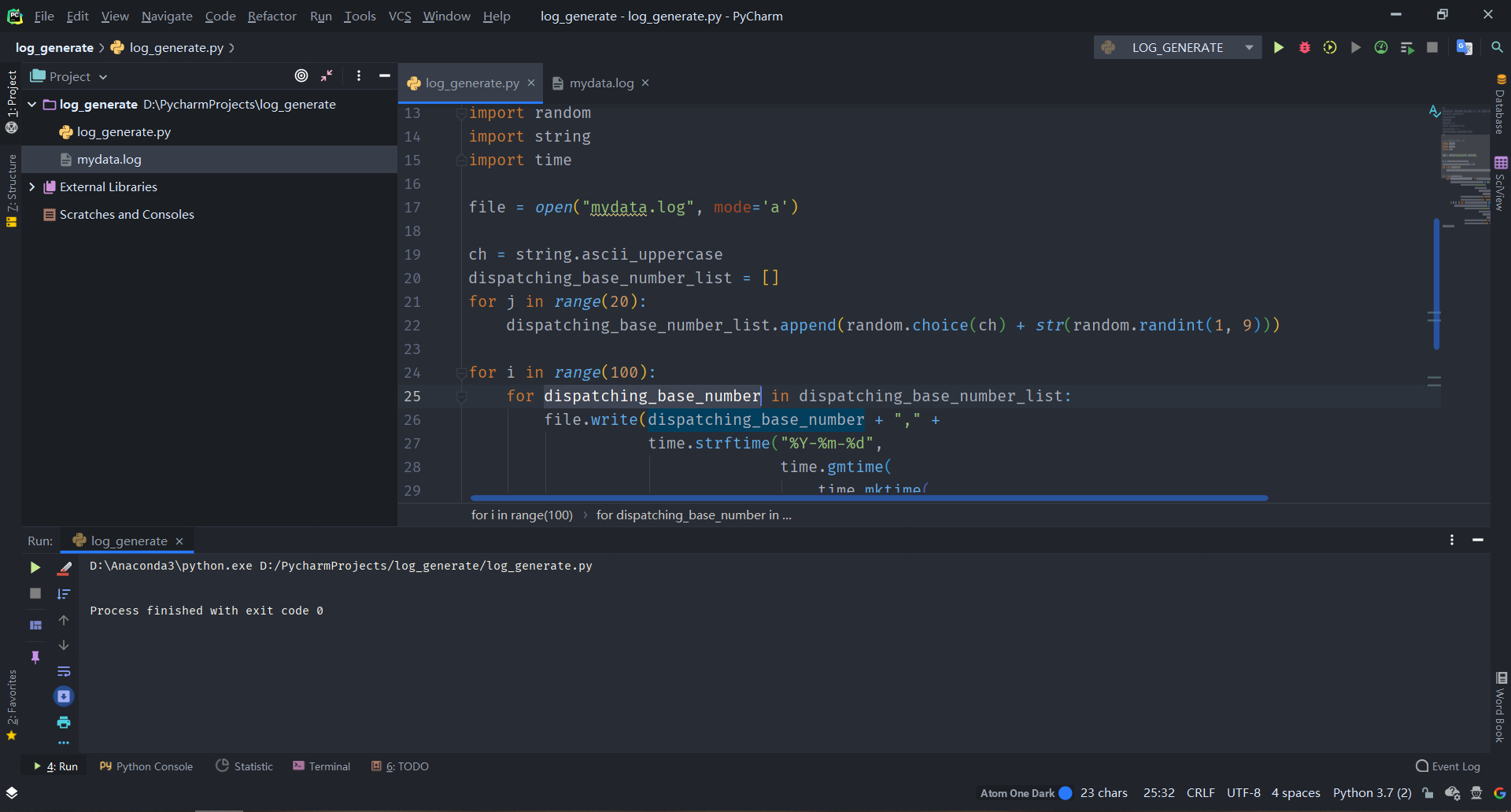
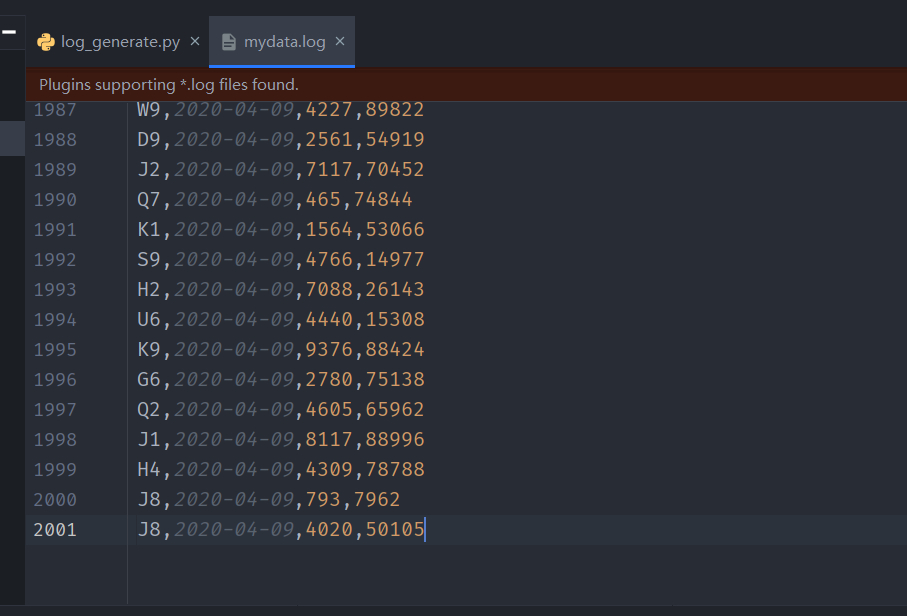
定义好了日志的格式,只要编写python程序,让他自己按照这个格式生产日志即可,具体代码见附录,下面是部分代码截图和运行结果:
4.2自选数据集计算的需求分析
因为是汽车和旅游日志信息,并且有不同日期,不同地区的信息,主要需求就是选取从开始时间到截止时间使用的机动车数量和旅游次数最多的前10个地区,以及他们的机动车总数量和旅游总次数。
主要步骤就是(与实验一大体相同,又有所区别):
按照 Serrializable 接口实现自定义排序的 Key;
将要进行二次排序的文件加载进来生成 key-value 类型的 RDD
使用 sortByKey 基于自定义的 Key 进行二次排序
去除掉排序的 key,只保留排序结果
排序规则如下:
以区域编号dispatching_base_number为基准,分别按照active_vehicles,trips,date进行降序排序。即先按照active_vehicles排序,如果active_vehicles相同,再比较trips,如果trips相同,再比较date,最后选择前10条记录输出。
4.3编程设计实现
4.3.1创建工程
4.3.1.1打开Eclipse IDE

4.3.1.2点击 File -> New ->Other
4.3.1.3搜索 maven -> 点击 Maven Project -> Next->Next
4.3.1.4选中maven-archetype-quickstart ->Next
4.3.1.5输入Group Id 为 org.zkpk;Artifact Id 为 spark ;Package为org.zkpk.spark;->Finish
4.3.1.6升级maven工程
升级完成:
4.3.1.7更改JRE,右键JRE System Library-> Properties
4.3.1.8选中jdk1.8.0_131-> OK
4.3.1.9点击spark项目->修改pom.xml-> 保存会自动下载jar包
4.3.1.10下载Jar包:
4.3.1.11最终 pom.xml 如下:
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
| <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.zkpk</groupId>
<artifactId>spark</artifactId>
<version>0.0.1</version>
<packaging>jar</packaging>
<name>spark</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.3.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/main/test</testSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>cn.com.syl.spark.App</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
|
4.3.1.12删除工程生成的App.java和AppTest.java
利用实验一的实验环境编写java程序,同样是SecondarySortKey.java和SecondarySortDemo.java两个java文件。其中SecondarySortKey.java中有两个类,一个是serDemo类,用于存储未排序的数据,一个是SecondarySortKey类,里面重写了一系列排序函数,用于按照自己的规则排序;SecondarySortDemo.java有一个类SecondarySortDemo,里面有主函数和创建Spark RDD,求和,sortByKey等函数,是主要的逻辑运行的地方。
4.3.2这里只挑出关键的代码进行解释注释和说明,详细的带注释的代码见附录:
这是排序的数据存放的类,有三个字段,全参构造函数,getter和setter,以及toString,hashCode和equal方法。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| public class SecondarySortKey implements Ordered<SecondarySortKey>, Serializable {
private static final long serialVersionUID = 3702442700882342403L;
private String date;
private int activeVehicles;
private int trips;
public SecondarySortKey() {
super();
}
public SecondarySortKey(String date, int activeVehicles, int trips) {
super();
this.date = date;
this.activeVehicles = activeVehicles;
this.trips = trips;
}
......
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
SecondarySortKey that = (SecondarySortKey) o;
return activeVehicles == that.activeVehicles &&
trips == that.trips &&
Objects.equals(date, that.date);
}
@Override
public int hashCode() {
return Objects.hash(date, activeVehicles, trips);
}
@Override
public String toString() {
return "SortResult{" +
"截止日期:" + date +
", 使用的机动车总数量:" + activeVehicles +
", 旅游总次数:" + trips +
'}';
}
}
|
最主要的是$greater,$less等一系列比较函数和compare和compareTo函数用于RDD的sortByKey。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| ......
public boolean $greater(SecondarySortKey other) {
if (activeVehicles > other.activeVehicles) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips > other.trips) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips == other.trips &&
date.compareTo(other.date) > 0) {
return true;
}
return false;
}
......
public int compare(SecondarySortKey other) {
if (activeVehicles - other.activeVehicles != 0) {
return activeVehicles - other.activeVehicles;
} else if (trips - other.trips != 0) {
return trips - other.trips;
}
return 0;
}
public int compareTo(SecondarySortKey other) {
if (activeVehicles - other.activeVehicles != 0) {
return activeVehicles - other.activeVehicles;
} else if (trips - other.trips != 0) {
return trips - other.trips;
}
return 0;
}
|
下面的类是主方法所在的类,也是主要的对数据进行处理计算的类:
他有四个函数(算上主函数),分别为:
main:
用于打开文件,创建SparkConf和SparkContext对象,调用函数对RDD进行操作,并输出结果。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setAppName("SecondarySortDemo").setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.setLogLevel("WARN");
JavaRDD<String> textfile = jsc.textFile("/home/zkpk/experiment/mydata.log");
JavaPairRDD<String, serDemo> pairRdd = mapTfRDD2Pair(textfile);
JavaPairRDD<String, serDemo> getlines = aggregateByDeviceID(pairRdd);
JavaPairRDD<SecondarySortKey, String> telval = mapRDDKey2SortKey(getlines);
JavaPairRDD<SecondarySortKey, String> sortedRdd = telval.sortByKey(false);
List<Tuple2<SecondarySortKey, String>> getTop = sortedRdd.take(10);
System.out.println("============ result ============");
for (Tuple2<SecondarySortKey, String> dt : getTop) {
System.out.println("区域编号:" + dt._2 + ", " + dt._1);
}
jsc.close();
}
|
mapTfRDD2Pair:
用于从文件中读取数据,并将其转化为JavaPairRDD,key为区域编号dispatchingBaseNumber,value为以文件每一行生成的serDemo对象。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| private static JavaPairRDD<String, serDemo> mapTfRDD2Pair(JavaRDD<String> accessLogRDD) {
return accessLogRDD.mapToPair(new PairFunction<String, String, serDemo>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, serDemo> call(String lines) throws Exception {
String[] split = lines.split(",");
String dispatchingBaseNumber = split[0];
String date = split[1];
int activeVehicles = Integer.valueOf(split[2]);
int trips = Integer.valueOf(split[3]);
serDemo dataInfo = new serDemo(date, activeVehicles, trips);
return new Tuple2<String, serDemo>(dispatchingBaseNumber, dataInfo);
}
});
}
|
aggregateByRegionID:
用于将mapTfRDD2Pair生成好的JavaPairRDD按照key对使用的机动车数量activeVehicles和旅游次数trips求和,获得JavaPairRDD,key为区域编号dispatchingBaseNumber,value为已经求和聚集完成的serDemo对象。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| private static JavaPairRDD<String, serDemo> aggregateByDeviceID(JavaPairRDD<String, serDemo> accessLogPairRDD) {
return accessLogPairRDD.reduceByKey(new Function2<serDemo, serDemo, serDemo>() {
private static final long serialVersionUID = 1L;
public serDemo call(serDemo d1, serDemo d2) throws Exception {
String date = d1.getDate().compareTo(d2.getDate()) > 0 ? d1.getDate() : d2.getDate();
int activeVehicles = d1.getActiveVehicles() + d2.getActiveVehicles();
int trips = d1.getTrips() + d2.getTrips();
serDemo accessLogInfo = new serDemo();
accessLogInfo.setDate(date);
accessLogInfo.setActiveVehicles(activeVehicles);
accessLogInfo.setTrips(trips);
return accessLogInfo;
}
});
}
|
mapRDDKey2SortKey:
用于将aggregateByRegionID生成好的JavaPairRDD按照上面定义好的规则进行排序,获得排好序的JavaPairRDD,用于输出。
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| private static JavaPairRDD<SecondarySortKey, String> mapRDDKey2SortKey(
JavaPairRDD<String, serDemo> aggrAccessLogPairRDD) {
return aggrAccessLogPairRDD.mapToPair(
new PairFunction<Tuple2<String, serDemo>, SecondarySortKey, String>() {
private static final long serialVersionUID = 1L;
public Tuple2<SecondarySortKey, String> call(Tuple2<String, serDemo> tuple) throws Exception {
String dispatchingBaseNumber = tuple._1;
serDemo accessLogInfo = tuple._2;
SecondarySortKey accessLogSortKey = new SecondarySortKey(accessLogInfo.getDate(), accessLogInfo.getActiveVehicles(),
accessLogInfo.getTrips());
return new Tuple2<SecondarySortKey, String>(accessLogSortKey, dispatchingBaseNumber);
}
});
}
|
4.4运行程序
4.4.1将生成好的mydata.log发送到平台。
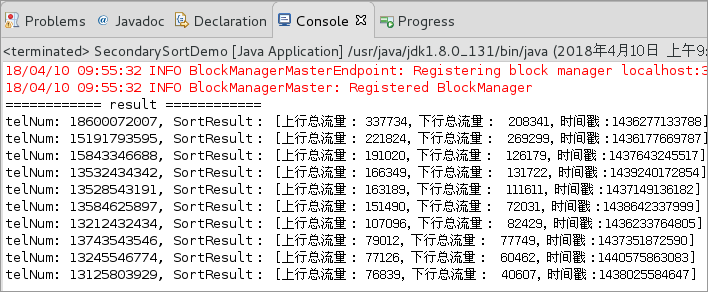
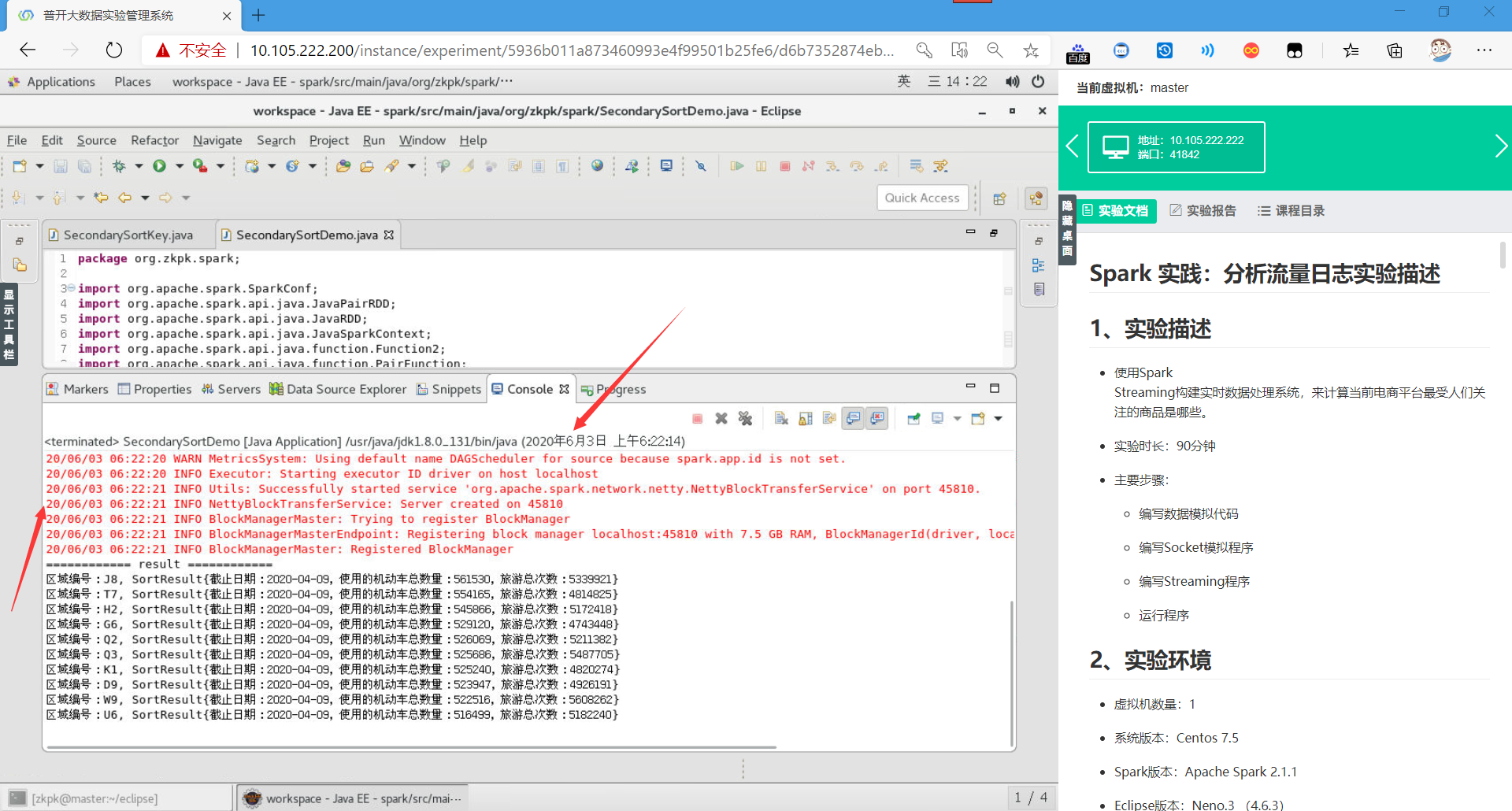
4.4.2运行程序,查看结果。
可以发现,程序正常运行得出了结果,并且已经求和和排序,成功!
五、附录
1、SecondarySortKey.java
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
| package org.zkpk.spark;
import scala.math.Ordered;
import java.io.Serializable;
import java.util.Objects;
class serDemo implements Serializable {
private static final long serialVersionUID = 5749943279909593929L;
private String date;
private int activeVehicles;
private int trips;
public serDemo() {
super();
}
public serDemo(String date, int activeVehicles, int trips) {
super();
this.date = date;
this.activeVehicles = activeVehicles;
this.trips = trips;
}
public static long getSerialVersionUID() {
return serialVersionUID;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public int getActiveVehicles() {
return activeVehicles;
}
public void setActiveVehicles(int activeVehicles) {
this.activeVehicles = activeVehicles;
}
public int getTrips() {
return trips;
}
public void setTrips(int trips) {
this.trips = trips;
}
}
public class SecondarySortKey implements Ordered<SecondarySortKey>, Serializable {
private static final long serialVersionUID = 3702442700882342403L;
private String date;
private int activeVehicles;
private int trips;
public SecondarySortKey() {
super();
}
public SecondarySortKey(String date, int activeVehicles, int trips) {
super();
this.date = date;
this.activeVehicles = activeVehicles;
this.trips = trips;
}
public static long getSerialVersionUID() {
return serialVersionUID;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public int getActiveVehicles() {
return activeVehicles;
}
public void setActiveVehicles(int activeVehicles) {
this.activeVehicles = activeVehicles;
}
public int getTrips() {
return trips;
}
public void setTrips(int trips) {
this.trips = trips;
}
public boolean $greater(SecondarySortKey other) {
if (activeVehicles > other.activeVehicles) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips > other.trips) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips == other.trips &&
date.compareTo(other.date) > 0) {
return true;
}
return false;
}
public boolean $greater$eq(SecondarySortKey other) {
if ($greater(other)) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips == other.trips &&
date.compareTo(other.date) == 0) {
return true;
}
return false;
}
public boolean $less(SecondarySortKey other) {
if (activeVehicles < other.activeVehicles) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips < other.trips) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips == other.trips &&
date.compareTo(other.date) < 0) {
return true;
}
return false;
}
public boolean $less$eq(SecondarySortKey other) {
if ($less(other)) {
return true;
} else if (activeVehicles == other.activeVehicles &&
trips == other.trips &&
date.compareTo(other.date) == 0) {
return true;
}
return false;
}
public int compare(SecondarySortKey other) {
if (activeVehicles - other.activeVehicles != 0) {
return activeVehicles - other.activeVehicles;
} else if (trips - other.trips != 0) {
return trips - other.trips;
}
return 0;
}
public int compareTo(SecondarySortKey other) {
if (activeVehicles - other.activeVehicles != 0) {
return activeVehicles - other.activeVehicles;
} else if (trips - other.trips != 0) {
return trips - other.trips;
}
return 0;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
SecondarySortKey that = (SecondarySortKey) o;
return activeVehicles == that.activeVehicles &&
trips == that.trips &&
Objects.equals(date, that.date);
}
@Override
public int hashCode() {
return Objects.hash(date, activeVehicles, trips);
}
@Override
public String toString() {
return "SortResult{" +
"截止日期:" + date +
", 使用的机动车总数量:" + activeVehicles +
", 旅游总次数:" + trips +
'}';
}
}
|
2、SecondarySortDemo.java
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| package org.zkpk.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.List;
public class SecondarySortDemo {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setAppName("SecondarySortDemo").setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.setLogLevel("WARN");
JavaRDD<String> textfile = jsc.textFile("/home/zkpk/experiment/mydata.log");
JavaPairRDD<String, serDemo> pairRdd = mapTfRDD2Pair(textfile);
JavaPairRDD<String, serDemo> getlines = aggregateByRegionID(pairRdd);
JavaPairRDD<SecondarySortKey, String> telval = mapRDDKey2SortKey(getlines);
JavaPairRDD<SecondarySortKey, String> sortedRdd = telval.sortByKey(false);
List<Tuple2<SecondarySortKey, String>> getTop = sortedRdd.take(10);
System.out.println("============ result ============");
for (Tuple2<SecondarySortKey, String> dt : getTop) {
System.out.println("区域编号:" + dt._2 + ", " + dt._1);
}
jsc.close();
}
private static JavaPairRDD<String, serDemo> mapTfRDD2Pair(JavaRDD<String> accessLogRDD) {
return accessLogRDD.mapToPair(new PairFunction<String, String, serDemo>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, serDemo> call(String lines) throws Exception {
String[] split = lines.split(",");
String dispatchingBaseNumber = split[0];
String date = split[1];
int activeVehicles = Integer.valueOf(split[2]);
int trips = Integer.valueOf(split[3]);
serDemo dataInfo = new serDemo(date, activeVehicles, trips);
return new Tuple2<String, serDemo>(dispatchingBaseNumber, dataInfo);
}
});
}
private static JavaPairRDD<String, serDemo> aggregateByRegionID(JavaPairRDD<String, serDemo> accessLogPairRDD) {
return accessLogPairRDD.reduceByKey(new Function2<serDemo, serDemo, serDemo>() {
private static final long serialVersionUID = 1L;
public serDemo call(serDemo d1, serDemo d2) throws Exception {
String date = d1.getDate().compareTo(d2.getDate()) > 0 ? d1.getDate() : d2.getDate();
int activeVehicles = d1.getActiveVehicles() + d2.getActiveVehicles();
int trips = d1.getTrips() + d2.getTrips();
serDemo accessLogInfo = new serDemo();
accessLogInfo.setDate(date);
accessLogInfo.setActiveVehicles(activeVehicles);
accessLogInfo.setTrips(trips);
return accessLogInfo;
}
});
}
private static JavaPairRDD<SecondarySortKey, String> mapRDDKey2SortKey(
JavaPairRDD<String, serDemo> aggrAccessLogPairRDD) {
return aggrAccessLogPairRDD.mapToPair(
new PairFunction<Tuple2<String, serDemo>, SecondarySortKey, String>() {
private static final long serialVersionUID = 1L;
public Tuple2<SecondarySortKey, String> call(Tuple2<String, serDemo> tuple) throws Exception {
String dispatchingBaseNumber = tuple._1;
serDemo accessLogInfo = tuple._2;
SecondarySortKey accessLogSortKey = new SecondarySortKey(accessLogInfo.getDate(), accessLogInfo.getActiveVehicles(),
accessLogInfo.getTrips());
return new Tuple2<SecondarySortKey, String>(accessLogSortKey, dispatchingBaseNumber);
}
});
}
}
|
3、log_generate.py
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import random
import string
import time
file = open("mydata.log", mode='a')
ch = string.ascii_uppercase
dispatching_base_number_list = []
for j in range(20):
dispatching_base_number_list.append(random.choice(ch) + str(random.randint(1, 9)))
for i in range(100):
for dispatching_base_number in dispatching_base_number_list:
file.write(dispatching_base_number + "," +
time.strftime("%Y-%m-%d",
time.gmtime(
time.mktime(
time.strptime("2020-01-02", "%Y-%m-%d")) + 86400 * i)) + "," +
str(random.randint(100, 10000)) + "," +
str(random.randint(1000, 100000)) + "\n")
if i == 99 and dispatching_base_number == dispatching_base_number_list[len(dispatching_base_number_list) - 1]:
file.write(dispatching_base_number + "," +
time.strftime("%Y-%m-%d",
time.gmtime(
time.mktime(
time.strptime("2020-01-02", "%Y-%m-%d")) + 86400 * i)) + "," +
str(random.randint(100, 10000)) + "," +
str(random.randint(1000, 100000)))
file.close()
|