







计算机系统结构 实验5 指令调度与延迟分支
本文是关于计算机系统结构实验五,指令调度与延迟分支。
一、实验目的
- 加深对指令调度技术的理解。
- 加深对延迟分支技术的理解。
- 熟练掌握用指令调度技术解决流水线中的数据冲突的方法。
- 进一步理解指令调度技术对 CPU 性能的改进。
- 进一步理解延迟分支技术对 CPU 性能的改进。
二、实验步骤及结果分析
1、启动 MIPSsim。
2、根据实验2的相关知识中关于流水线各段操作的描述,进一步理解流水线窗口中各段的功能,掌握各流水线寄存器的含义(双击各段,就可以看到各流水线寄存器中的内容)。
①IF段:
②ID段:
③EX段:
④MEM段:
⑤WB段:
3、选择“配置”→“流水方式”选项,使模拟器工作在流水方式下。
4、用指令调度技术解决流水线中的结构冲突与数据冲突:
启动 MIPSsim。用 MIPSsim 的“文件”->“载入程序”选项来加载 schedule.s(在模拟器所在文件夹下的“样例程序”文件夹中)。关闭定向功能,这是通过“配置“->”定向“选项来实现的。执行所载入的程序,通过查看统计数据和时钟周期图,找出并记录程序执行过程中各种冲突发生的次数,发生冲突的指令组合以及程序执行的总时钟周期数。
载入的程序:
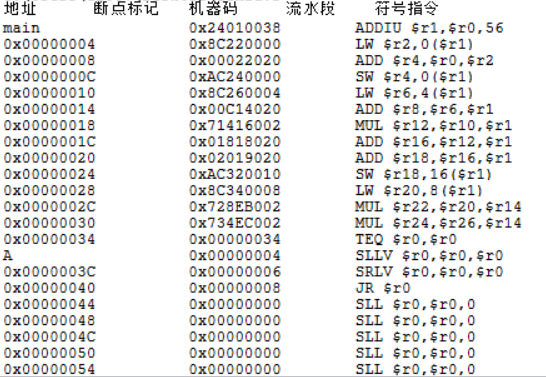
执行结果:
寄存器的值

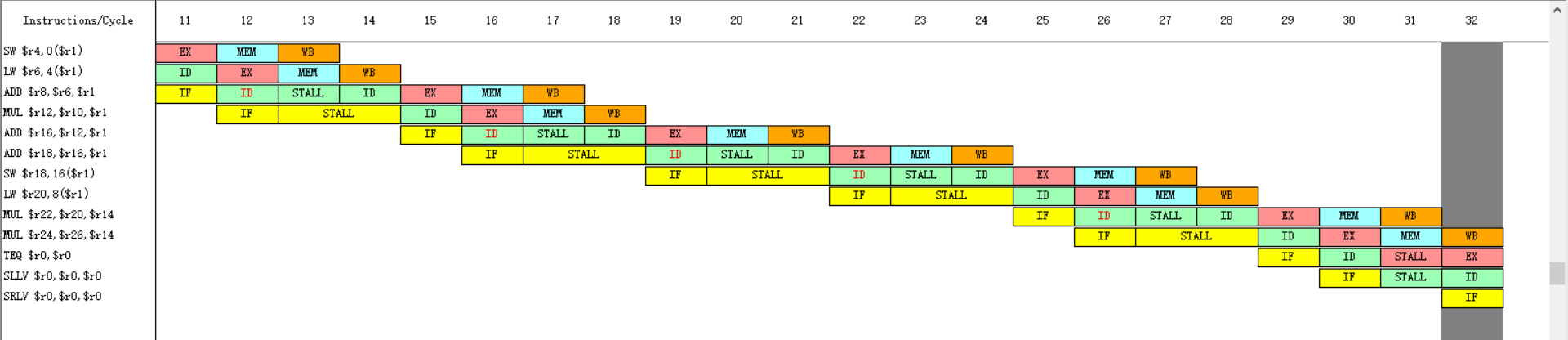
部分时钟周期图
统计

发现总共执行了33个周期,执行了15条指令,8次RAW停顿,RAW停顿有16个周期,RAW停顿占周期总数的百分比为48.48485%,所有的停顿为17个周期,占周期总数的百分比为51.51515%。
$$
吞吐率TP_1=\frac{15}{33\Delta{t}}
$$$$
加速比S_1=\frac{15\times{5\Delta{t}}}{33\Delta{t}}\approx{2.27}
$$冲突的指令组合:
1-1和2-1,2-1和2-2,2-2和2-3,3-1和3-2,4-1和4-2,4-2和4-3,4-3和4-4,5-1和5-2共8对冲突,1-5组组内冲突,组间没有关联。
schedule.s:
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26.text
main:
ADDIU $r1,$r0,A # 1-1
LW $r2,0($r1) # 2-1
ADD $r4,$r0,$r2 # 2-2
SW $r4,0($r1) # 2-3
LW $r6,4($r1) # 3-1
ADD $r8,$r6,$r1 # 3-2
MUL $r12,$r10,$r1 # 4-1
ADD $r16,$r12,$r1 # 4-2
ADD $r18,$r16,$r1 # 4-3
SW $r18,16($r1) # 4-4
LW $r20,8($r1) # 5-1
MUL $r22,$r20,$r14 # 5-2
MUL $r24,$r26,$r14 # 6-1
TEQ $r0,$r0 # 7-1
.data
A:
.word 4,6,8
自己采用调度技术对程序进行指令调度,消除冲突(自己修改源程序)。将调度(修改)后的程序重新命名为 afer-schedule.s。(注意:调度方法灵活多样,在保证程序正确性的前提下自己随意调度,尽量减少冲突即可,不要求要达到最优。)载入 afer-schedule.s,执行该程序,观察程序在流水线中的执行情况,记录程序执行的总时钟周期数。 比较调度前和调度后的性能,论述指令调度对提高 CPU 性能的作用。
PS:调度后的程序见附录。
载入的程序:
执行结果:
寄存器的值

与不调度前完全一致,调度没有改变结果,调度正确。
时钟周期图
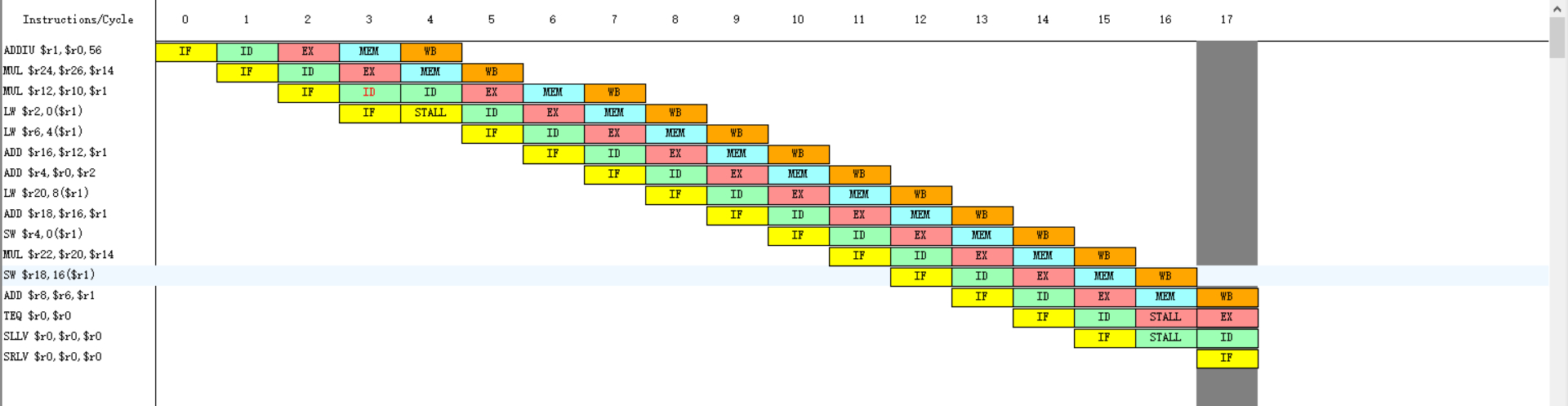
统计

发现总共执行了18个周期,执行了15条指令,1次RAW停顿,RAW停顿有1个周期,RAW停顿占周期总数的百分比为5.555555%,较没有静态调度的48.48485%少了很多,所有的停顿为2个周期,占周期总数的百分比为11.111111%,较没有静态调度的51.51515%也少了很多。
$$
吞吐率TP_2=\frac{15}{18\Delta{t}}
$$$$
加速比S_2=\frac{15\times{5\Delta{t}}}{18\Delta{t}}\approx{4.17}
$$吞吐率和加速比是没有静态调度时的$\frac{33}{18}\approx{1.83}$倍。
5、用延迟分支技术减少分支指令对性能的影响:
在 MIPSsim 中载入 branch.s 样例程序(在本模拟器目录的“样例程序”文件夹中。关闭延迟分支功能。这是通过在“配置”->“延迟槽”选项来实现的。执行该程序,观察并记录发生分支延迟的时刻,记录该程序执行的总时钟周期数。
载入的程序:

执行结果:
寄存器的值

部分时钟周期图
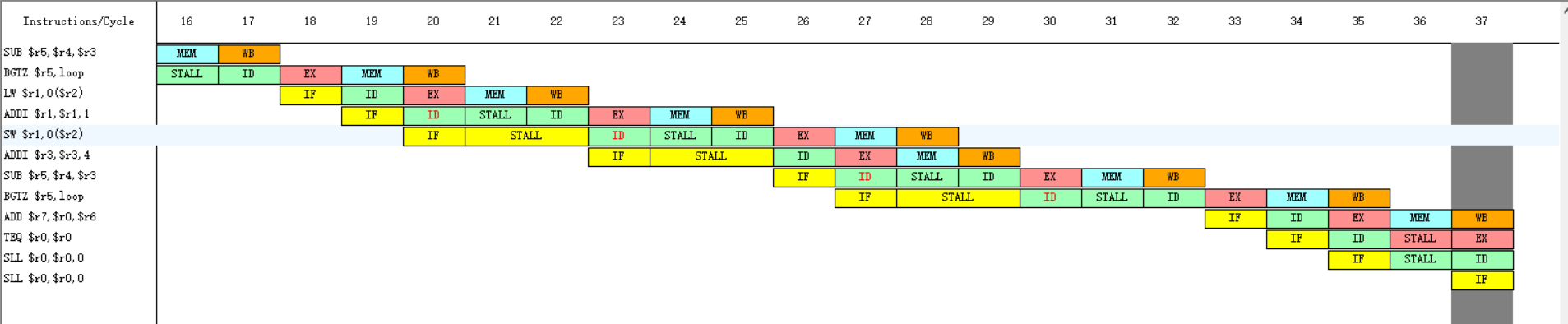
统计

发现总共执行了38个周期,执行了18条指令,8次RAW停顿,RAW停顿有16个周期,RAW停顿占周期总数的百分比为42.10526%,控制停顿有2个周期,占周期总数的百分比为5.263158%,所有的停顿为19个周期,占周期总数的百分比为50%。发生分支延迟的时刻为第15个周期,延迟了2个周期。
 $$
吞吐率TP_1=\frac{18}{38\Delta{t}}
$$
$$
吞吐率TP_1=\frac{18}{38\Delta{t}}
$$
$$
加速比S_1=\frac{18\times{5\Delta{t}}}{38\Delta{t}}\approx{2.37}
$$冲突的指令组合:
2-1和2-2,2-2和2-3,3-1和3-2,3-2和3-3共4对冲突,2组和3组组内冲突,组间没有关联。
branch.s:
点击查看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18.text
main:
ADDI $r2,$r0,1024 # 1-1
ADD $r3,$r0,$r0 # 1-2
ADDI $r4,$r0,8 # 1-3
loop:
LW $r1,0($r2) # 2-1
ADDI $r1,$r1,1 # 2-2
SW $r1,0($r2) # 2-3
ADDI $r3,$r3,4 # 3-1
SUB $r5,$r4,$r3 # 3-2
BGTZ $r5,loop # 3-3
ADD $r7,$r0,$r6 # 4-1
TEQ $r0,$r0 # 5-1
假设延迟槽为一个,自己对 branch.s 程序进行指令调度(自己修改源程序),将调度后的程序重新命名为 delayed-branch.s。 载入 delayed-branch.s,打开延迟分支功能,执行该程序,观察其时钟周期图,记录程序执行的总时钟周期数。
PS:调度后的程序见附录。
载入的程序:
执行结果:
寄存器的值

与不调度前完全一致,调度没有改变结果,调度正确。
部分时钟周期图
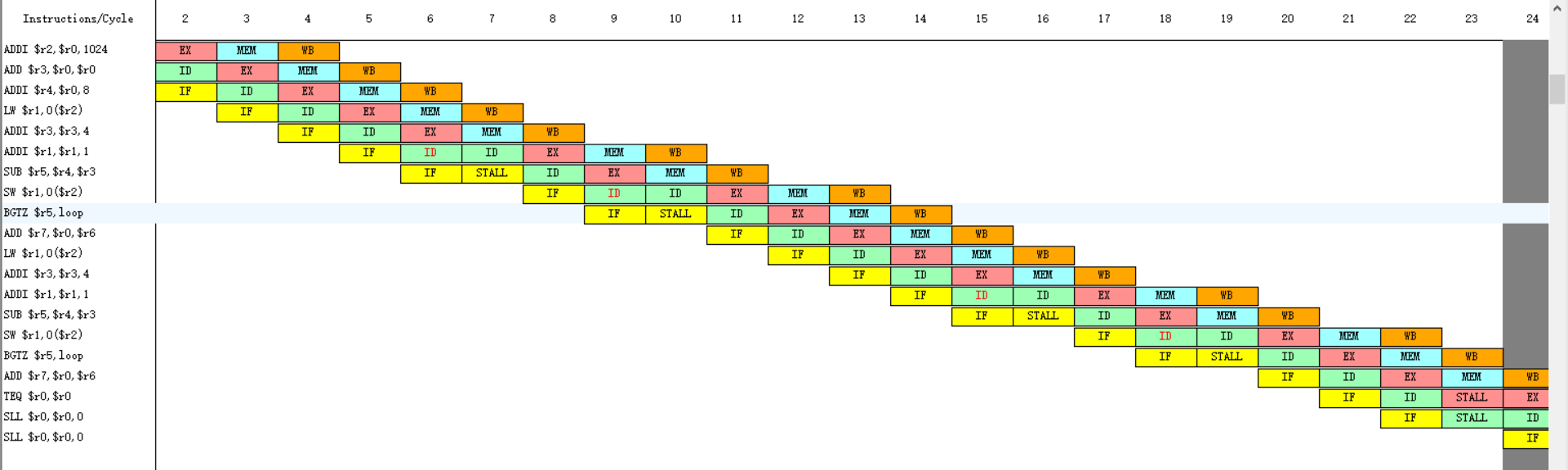
统计

发现总共执行了25个周期,执行了19条指令,4次RAW停顿,RAW停顿有4个周期,RAW停顿占周期总数的百分比为16%,较没有静态调度的42.10526%少了很多,控制停顿有0个周期,占周期总数的百分比为0%,比没有使用延迟分支技术的5.263158%少了,所有的停顿为5个周期,占周期总数的百分比为20%,较没有静态调度和延迟分支技术的50%也减少了。可以发现使用延迟分支技术后,控制停顿消失了。
$$
吞吐率TP_2=\frac{19}{25\Delta{t}}
$$$$
加速比S_2=\frac{19\times{5\Delta{t}}}{25\Delta{t}}={3.8}
$$吞吐率和加速比是没有静态调度和延迟分支技术时的$\frac{19\times{38}}{25\times{18}}\approx{1.60}$倍。
四、实验结论
静态调度优化代码和定向技术都能在一定程度上减少甚至消除数据冲突,尤其是RAW停顿,可以很好地提高性能,但是这两种方法对分支控制停顿没有任何帮助。但是延迟分支技术是由编译器通过重排指令序列,在分支指令后紧跟一条或几条延迟槽指令,不管分支是否成功,都顺序执行延迟槽中的指令,从而逻辑上“延长”分支指令的执行时间,减少甚至消除了控制停顿。因此这几种方法都能大幅度的减少停顿,从而提高CPU性能。
在查看延迟分支技术的统计信息时,发现使用延迟分支技术比不使用延迟分支技术多执行了一条指令,可能是由于分支取消机制当分支的实际执行方向和事先所预测的一样时,执行分支延迟槽中的指令,否则就将分支延迟槽中的指令转化成一个空操作,这条指令确实已经执行了,只是分支条件判断完后发现不该执行,然后就将执行的回滚,因此比不使用延迟分支技术多执行了一条指令。
五、附录
1、after-schedule.s
点击查看代码
1 | .text |
2、delay-branch.s
点击查看代码
1 | .text |

本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议

