本文是关于Linux中的shell脚本程序设计,有几个小Demo。
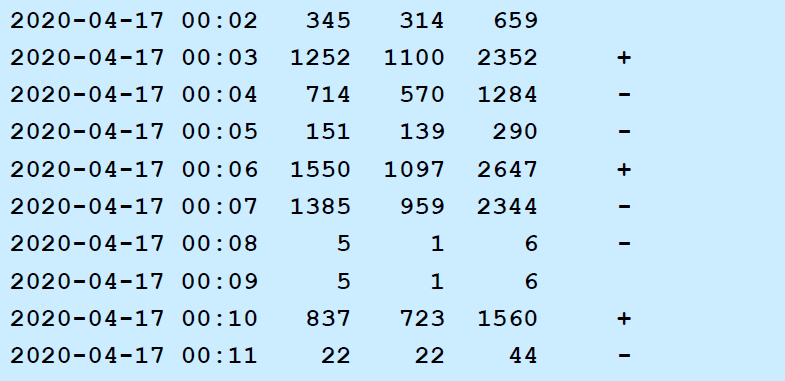
一、题目要求 1、生成TCP 活动状况报告 netstat –statistics 命令可以列出tcp等协议的统计信息。编写 shell 脚本程序,每隔1分钟生成1行信息:当前时间;这一分钟内 TCP 发送了多少报文;接收了多少报文;收发报文总数;行尾给出符号+或-或空格(+表示这分钟收发报文数比上分钟多10包以上,差别在 10 包或以内用空格,否则用符号-)。
运行示例如下:
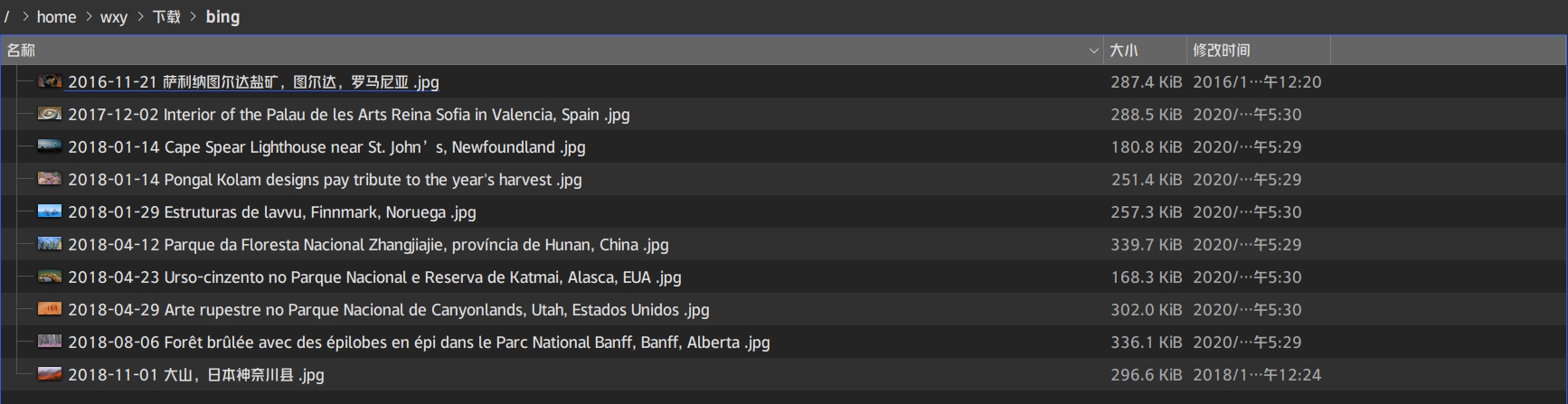
2、下载bing 图库中图片 编写脚本程序bing.sh ,将访问这个图库 中照片全部下载下来存放到本地 bing 目录中,上面 URL 中p=23 可以换成 p=1 到p=126 可访问 126 个页,每页有 12 个图,每个图的日期,中文说明信息和下载地址及文件名 html 文件中可提取。要求下载后的文件命名为“ 日期 中文说明 .jpg ”
例如
2019-08-03 野花草甸上的一只欧亚雕鸮,德国莱茵兰 普法尔茨 .jpg
命令行参数
要允许多个程序并发
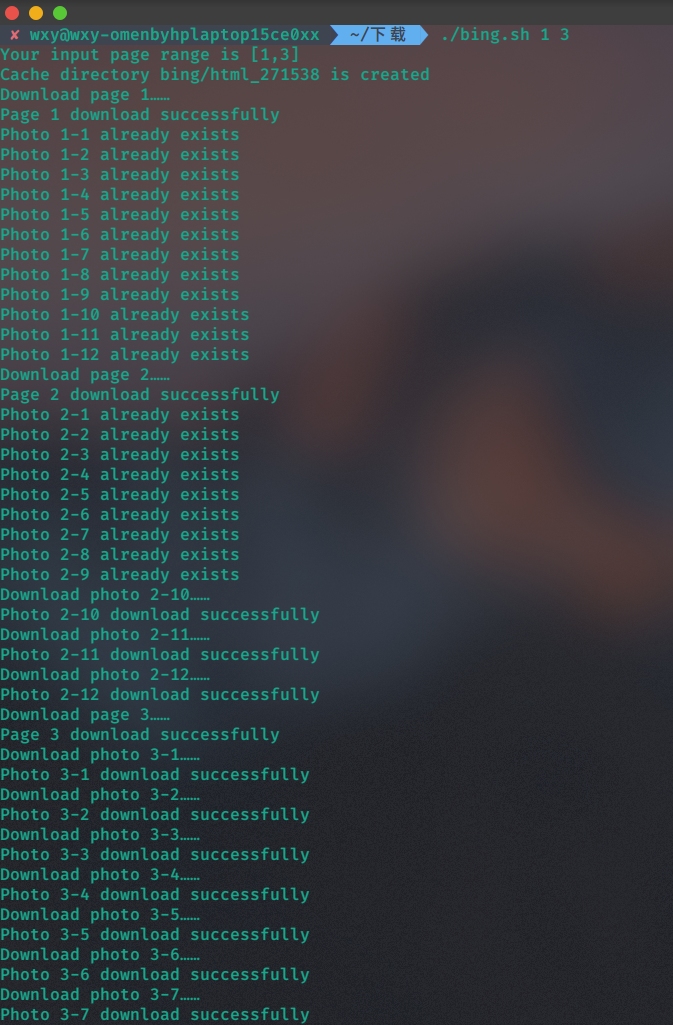
例如:一个终端上启动 ./bing.sh 1 63 ,另一个终端上启动 ./bing.sh 64 126 ,这样在两个终端上同时下载,以加快任务完成的速度。
不重复下载已下载的图片
检查图片是否已下载,如果已下载,则不再下载,这样在一定程度上支持批量任务在被中断后可以从断点继续。
考虑下载文件出现故障的情况
如果一 个图片有 5MB ,接收 1.5MB 后网络断开,则残存一个不完整的图片文件。避免这种现象发生的一种方法是, wget 下载时使用一个临时文件名。判断 wget 是否成功,若成功则将文件改名为正式名称;若失败,删除临时文件。临时文件名的选取要考虑前述的并发问题,至少不可以固定一个名字导致两进程的争夺。
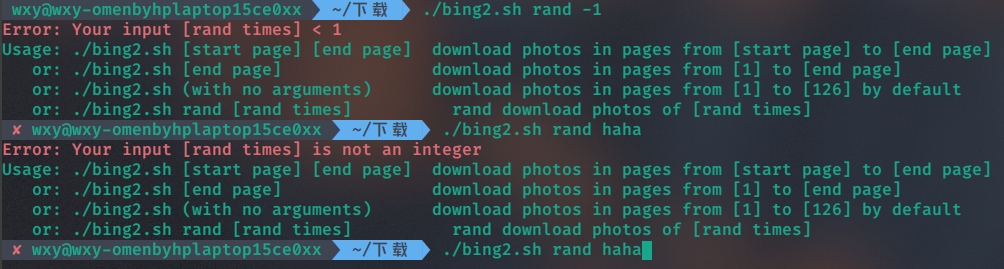
3、选做:获取更多图片 对已设计好的bing sh 进一步扩充,允许下面的命令行参数:
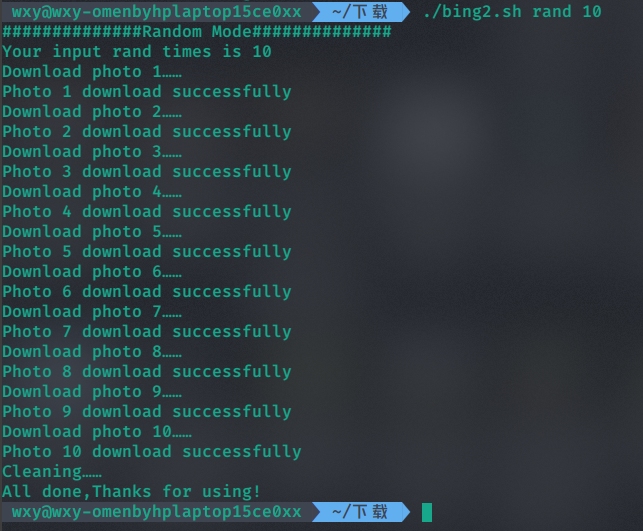
实现的功能为:执行500 次随机获取。每次成功的随机获取会得到一个图片,检查一下这个图片是否本地已存在。如果已存在,丢弃,否则保存。
访问https ://bing.ioliu.cn/v1/rand? json 可得到一个 json 数据,每次得到的内容是随机的,其中含有图片的日期、说明信息和获取它的 url 网址。新获得的文件命名方式与以前的程序相同。要求:文件名不同但是内容完全相同的图片丢弃,例如,下面两个文件虽然名字不同,但是内容是一样的,只保留其中一个文件。
2019-05-03 Ruff male displaying its plumage, Varanger Peninsula, Norway.jpg
2019-05-02 挪威瓦朗厄尔半岛上一只展示翎颌的雄性涉禽.jpg
二、实验环境 系统:Manjaro 20.0 基于 Arc Linux
编辑器:Visual Studio Code
三、实验步骤 1、生成TCP 活动状况报告
先在终端中运行命令查看输出
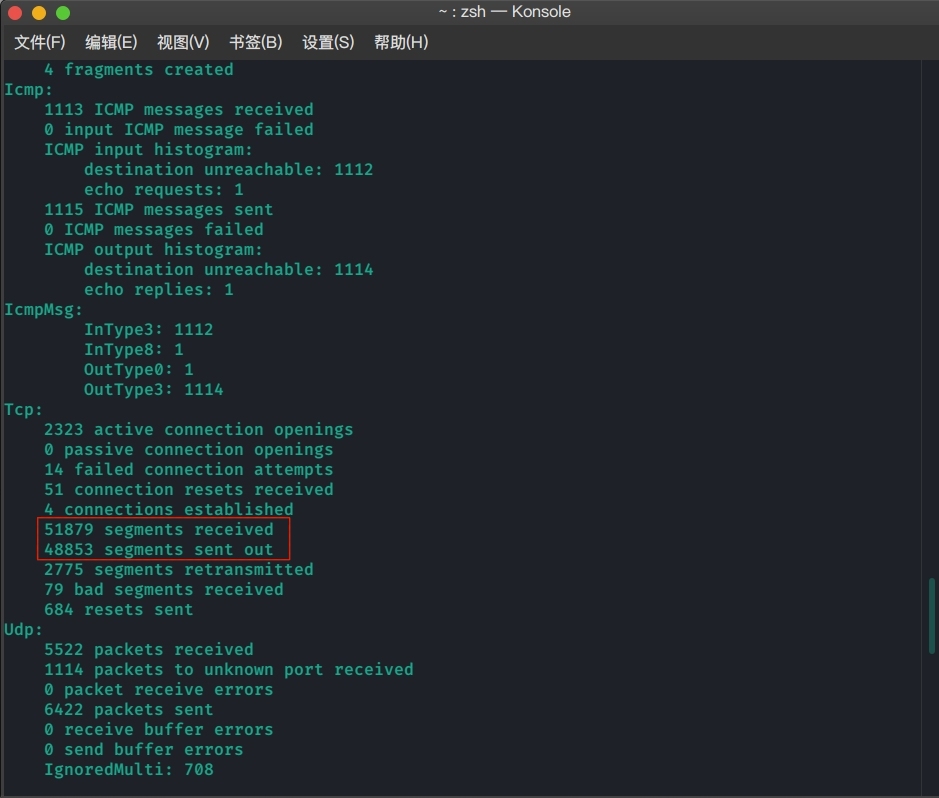
可以在Tcp下看到相关信息,我们感兴趣的内容是的上图红框圈起的部分,因此我们可以使用正则表达式配合grep、sed、awk命令,将它取出来。
1 netstat --statistics | grep segments
发现还不够,继续使用grep提取:
1 netstat --statistics | grep '[0-9][0-9]* segments
再添加一个过滤条件,最终成功获取了所需信息。
1 netstat --statistics | grep '[0-9][0-9]* segments [rs][e][cn]
这样,我们就可以直接使用awk命令,获取所需的列即可。
1 netstat --statistics | awk '/[0-9][0-9]* segments [rs][e][cn]/ {print $1}'
使用date命令,可以获取当前日期时间。
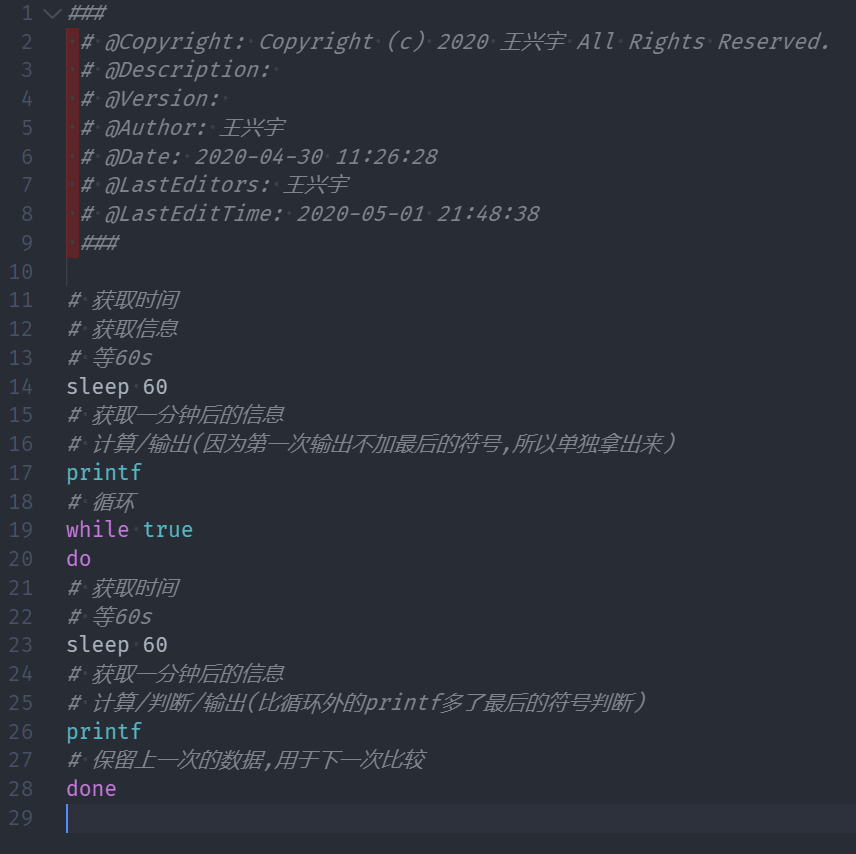
因为要隔一分钟获取一次,程序的基本框架就是:
详细的代码以及注释在最后的附录中,这里不再展示。
编写完后运行net.sh,发现不能运行,加上可执行权限即可。
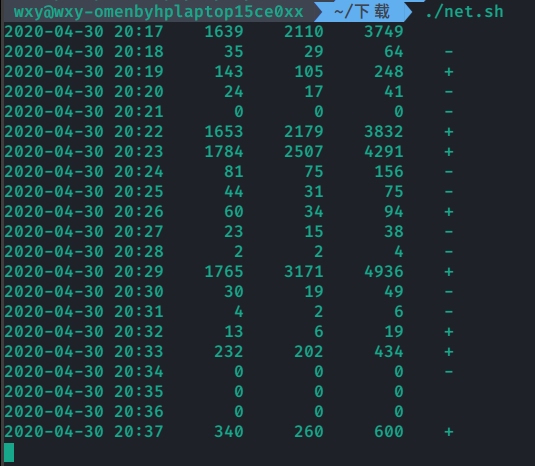
运行程序
2、下载bing 图库中图片
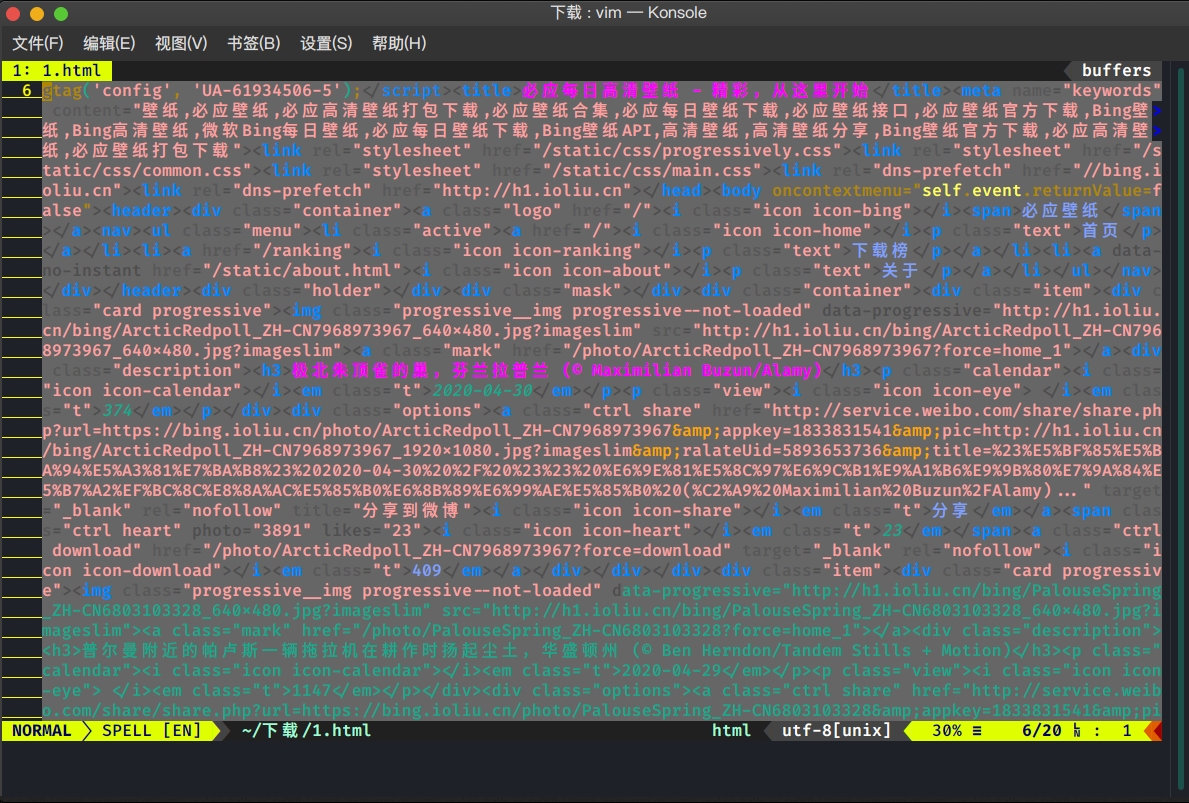
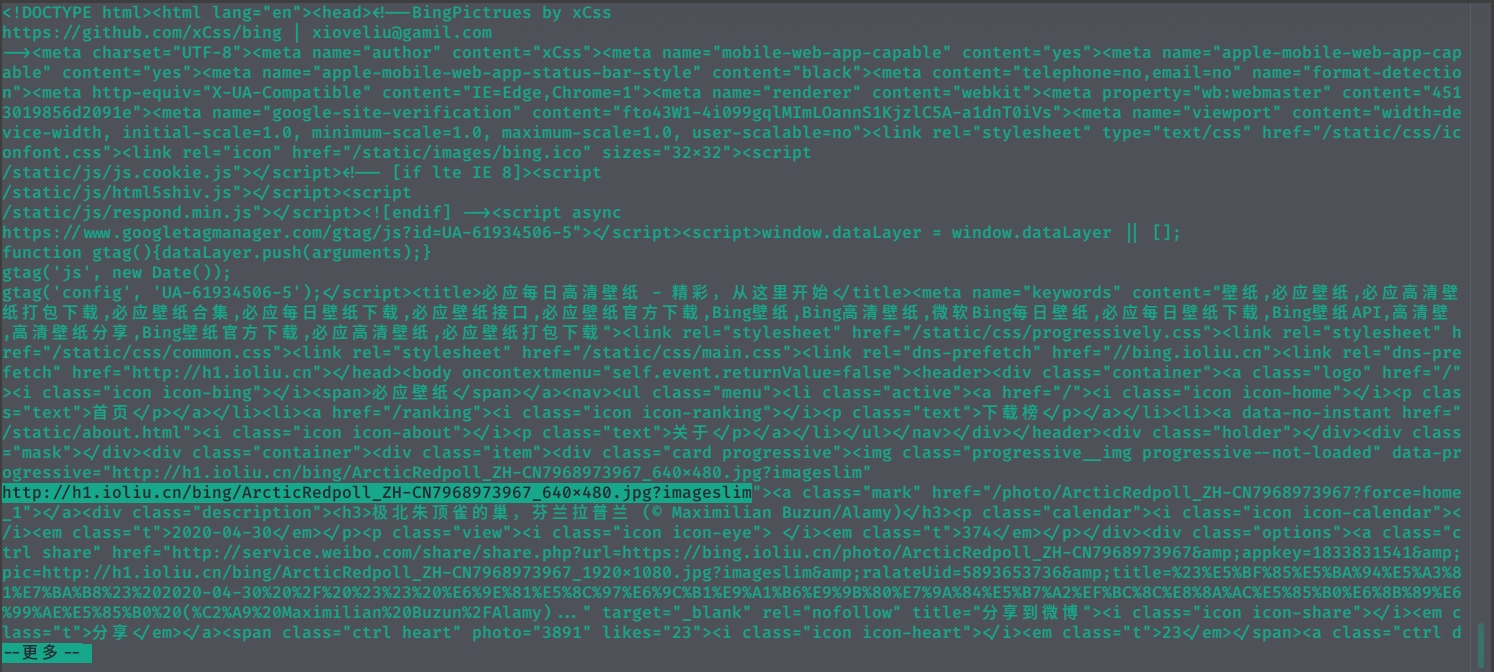
先去bing图库 看一下网页的源码。
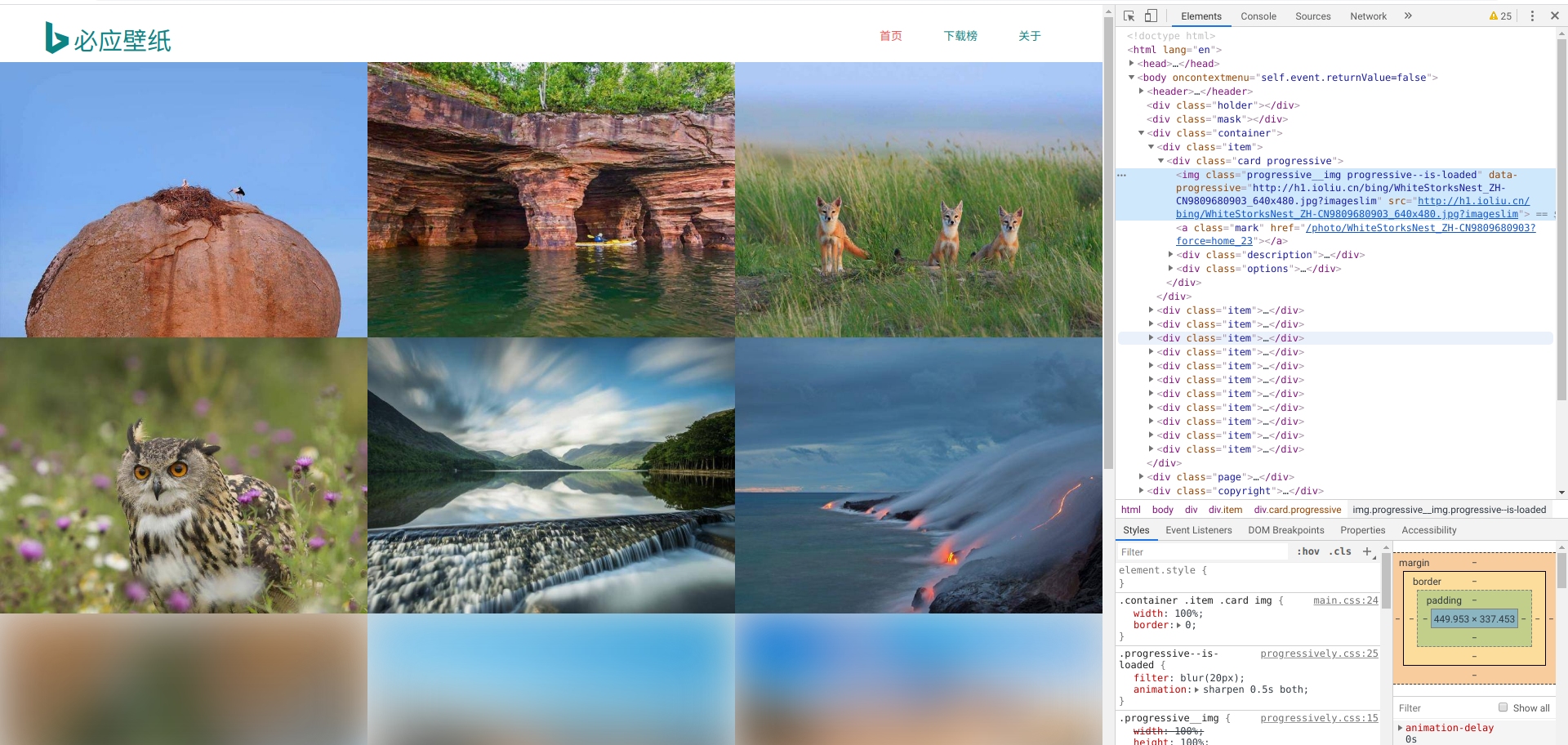
打开开发者工具。
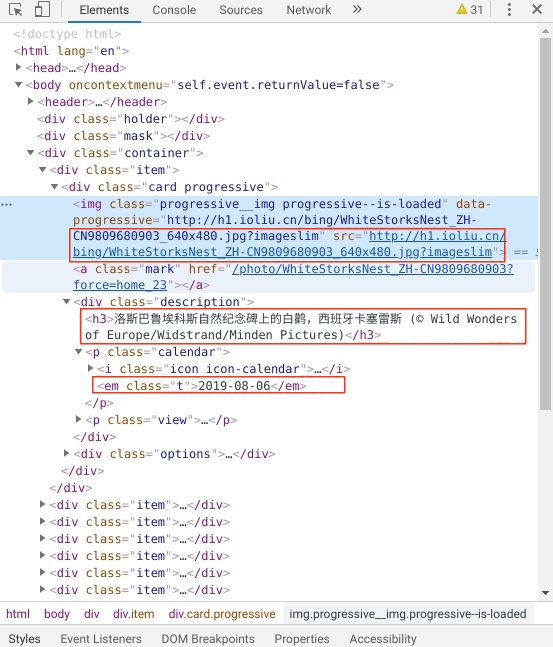
我们感兴趣的内容即为下图中用红框圈起的3个部分。
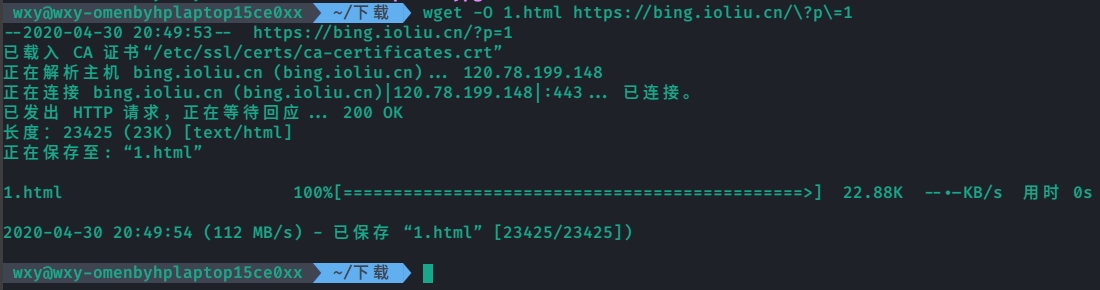
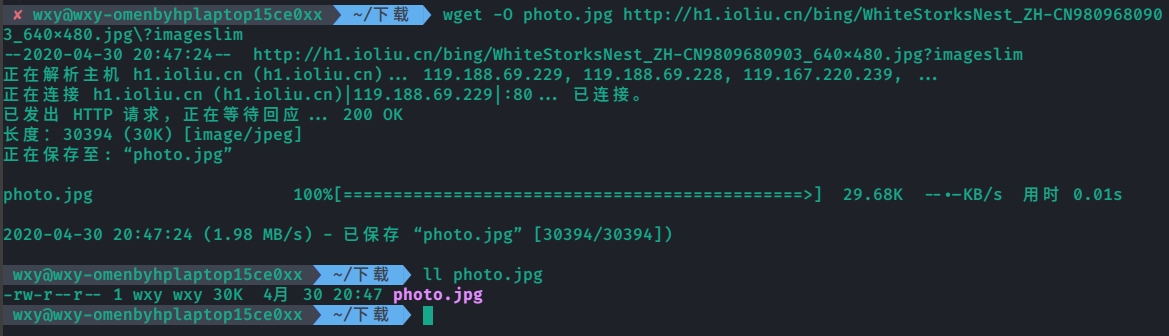
使用wget命令尝试下载网页和图片。
1 2 wget -O 1.html https://bing.ioliu.cn/\?p\=1 wget -O photo.jpg http://h1.ioliu.cn/bing/WhiteStorksNest_ZH-CN9809680903_640x480.jpg\?imageslim
查看下载的内容。
网页:
图片:
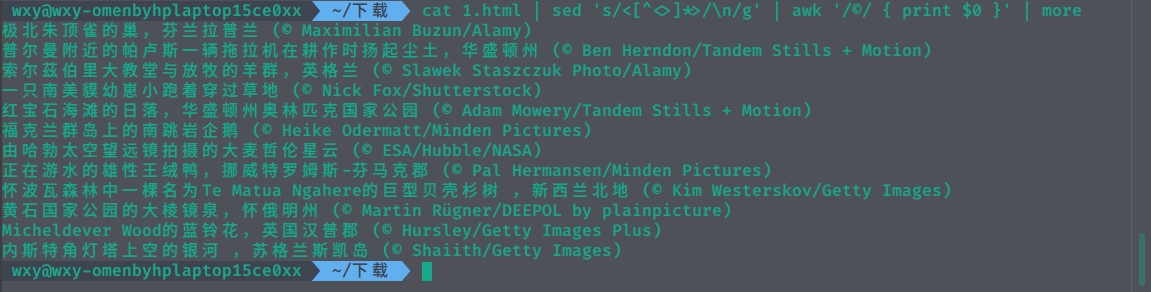
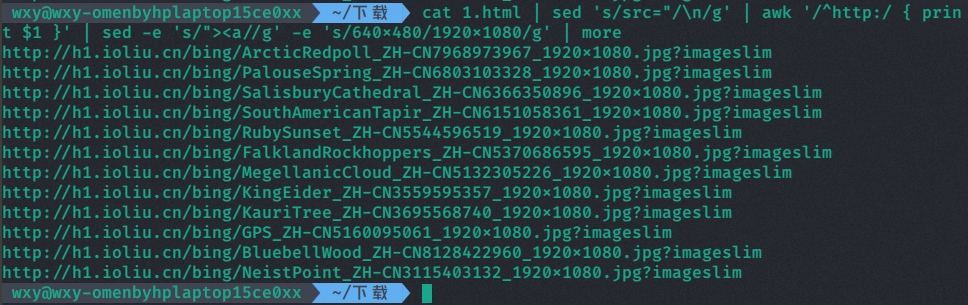
下面进行把html中我们感兴趣的内容通过正则表达式配合grep、sed、awk命令,将它取出来。
详细的代码和注释见最后的附录。
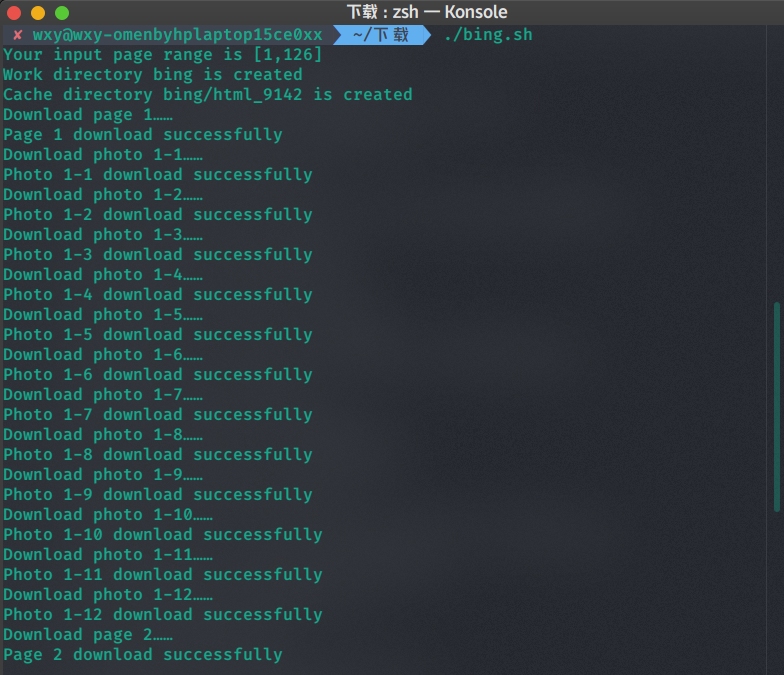
运行程序,依然需要先赋予执行权限。
不带参数
发现程序正常运行。
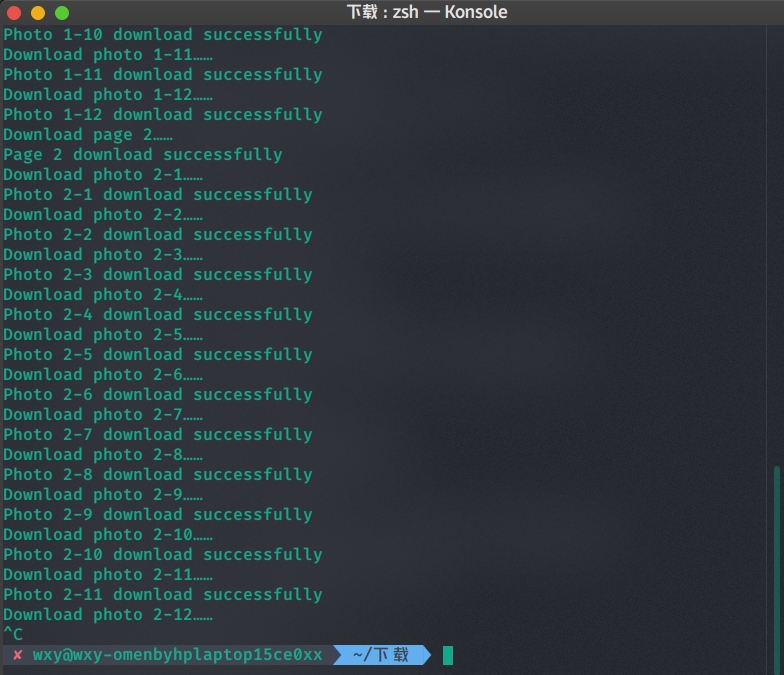
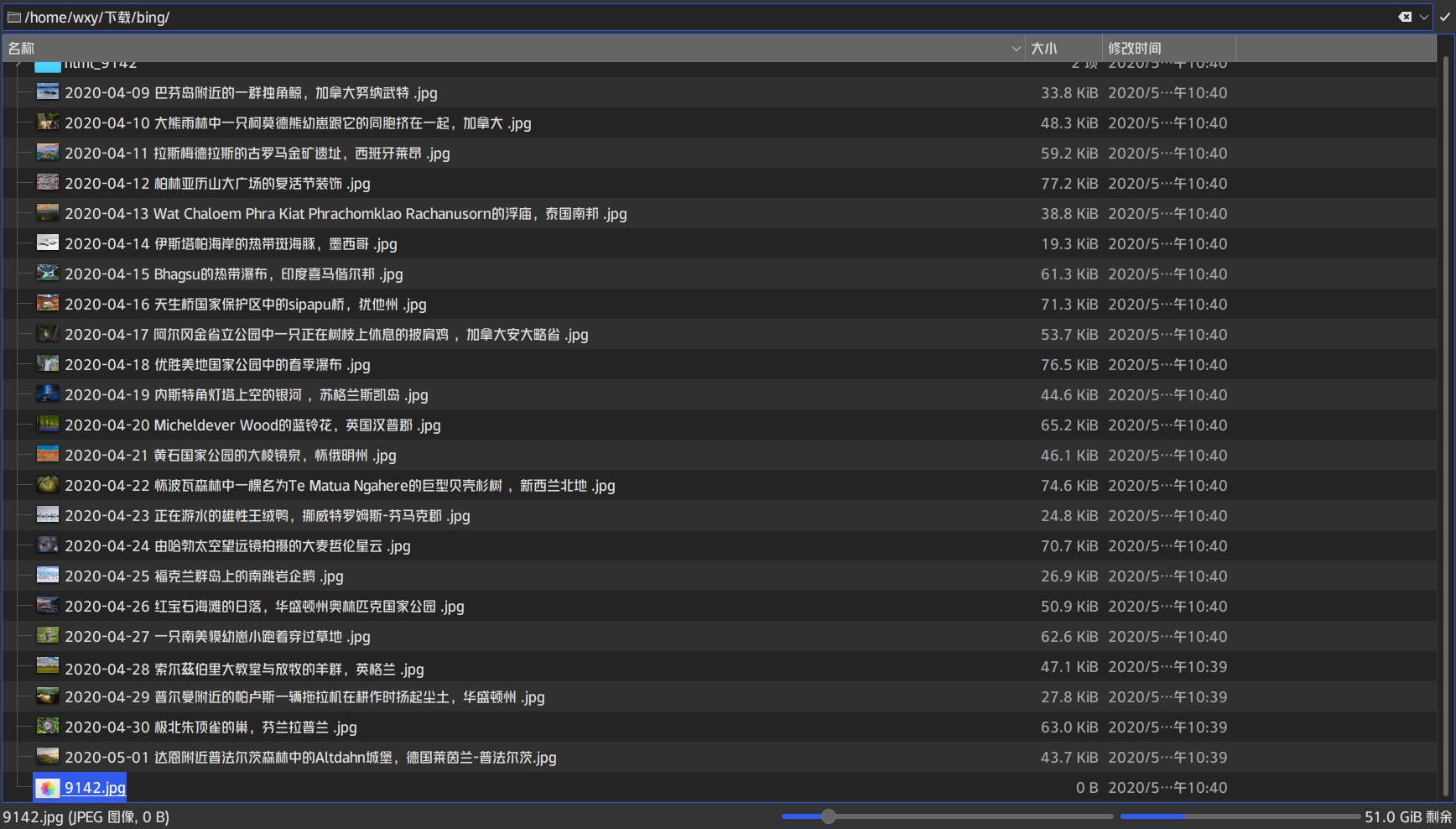
在运行过程中故意强制退出。
因为程序强制退出,会留下一个下载未完全的文件。但是完全不会受到影响,下一次运行时,会自动接续下载。
两个参数
因为上一个命令已经下载了一部分,已经下载过的不会再下载,接着上一次下载的位置继续下载。
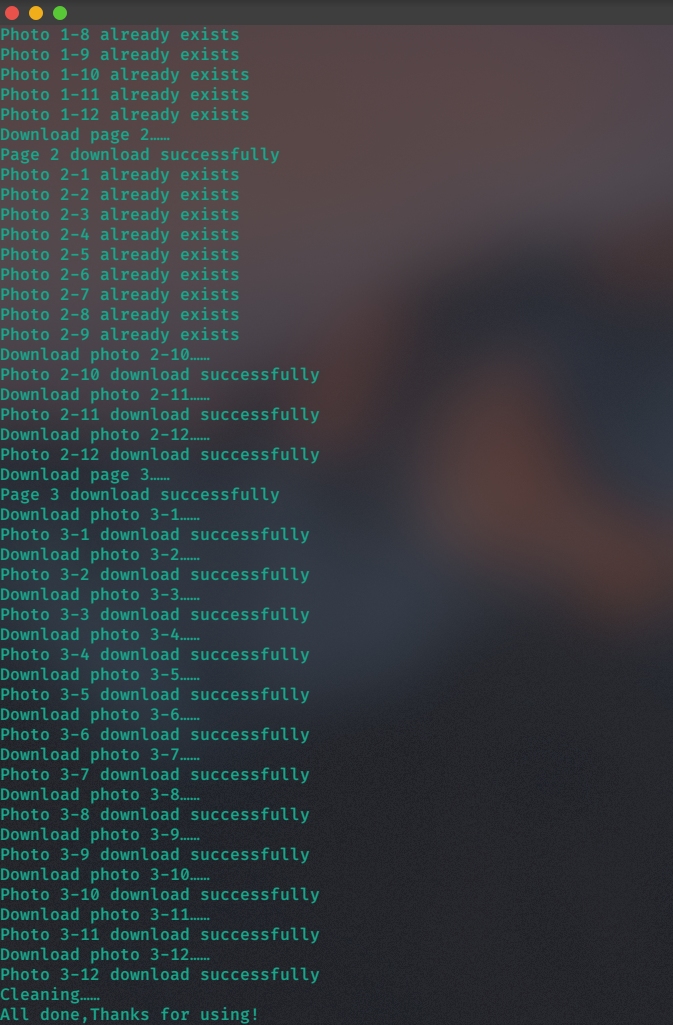
下载完成。
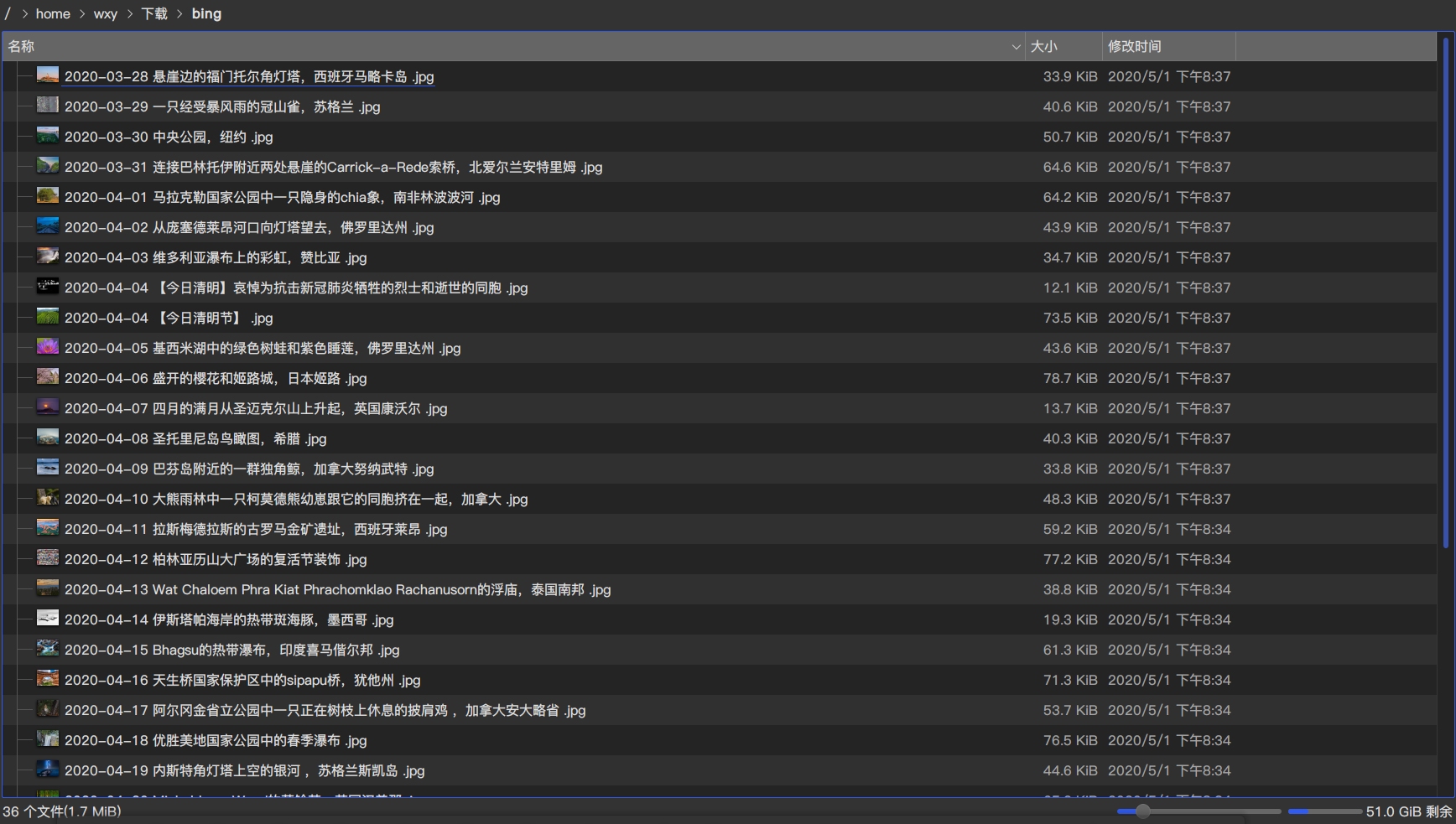
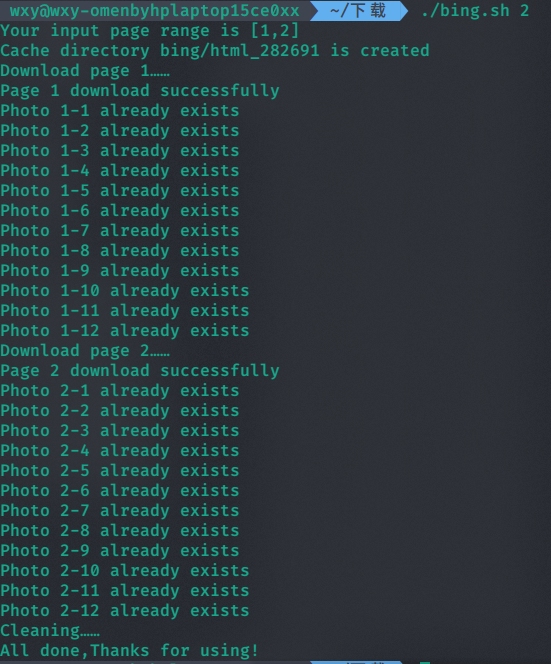
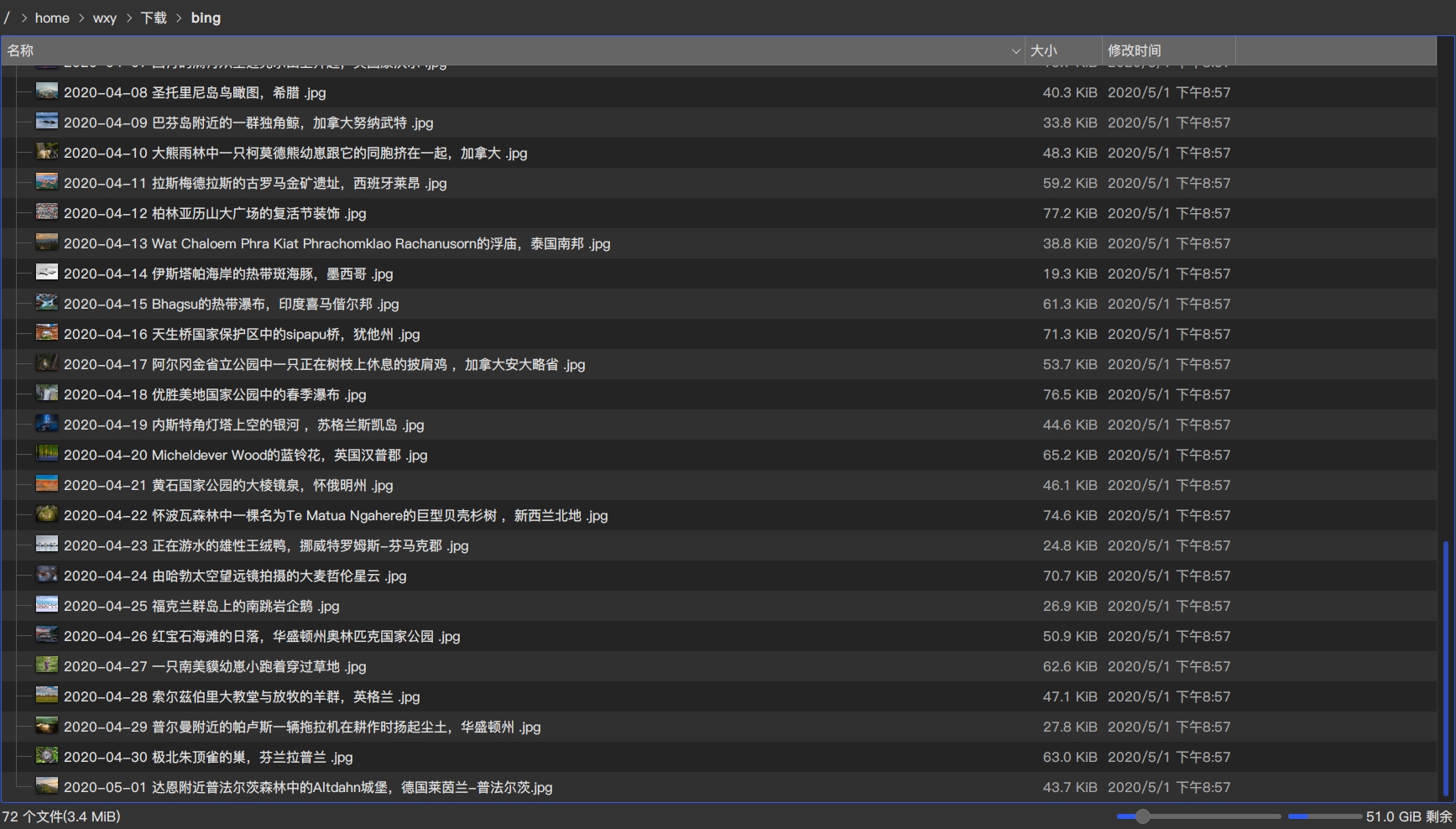
查看下载的图片,发现是刚好36张,1-3页。
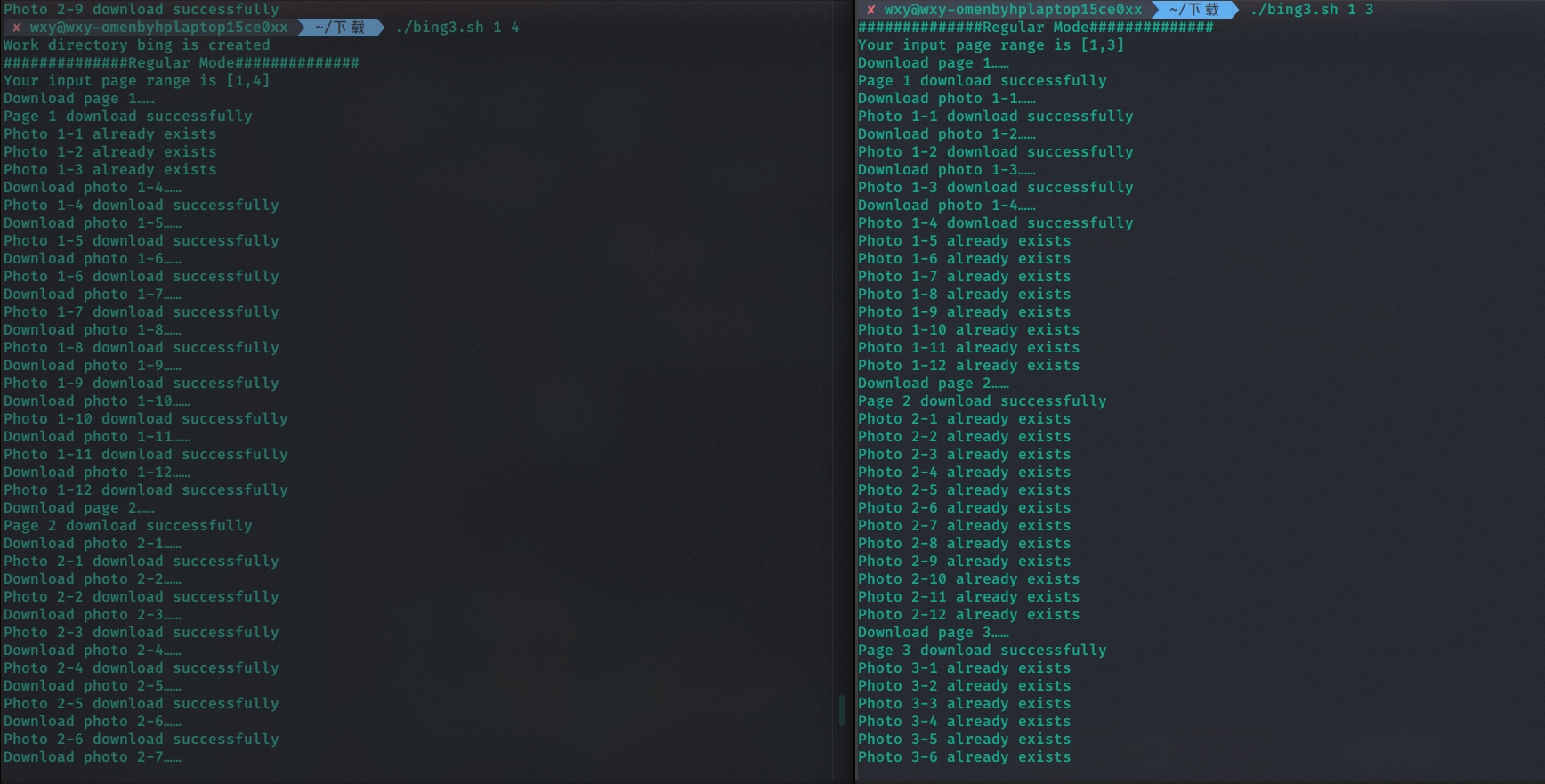
一个参数(自己额外实现的功能)
如果只输入一个参数,那么将从第一页下载到输入的参数页数。
因为上面已经下载了1-3页,因此不会重复下载。
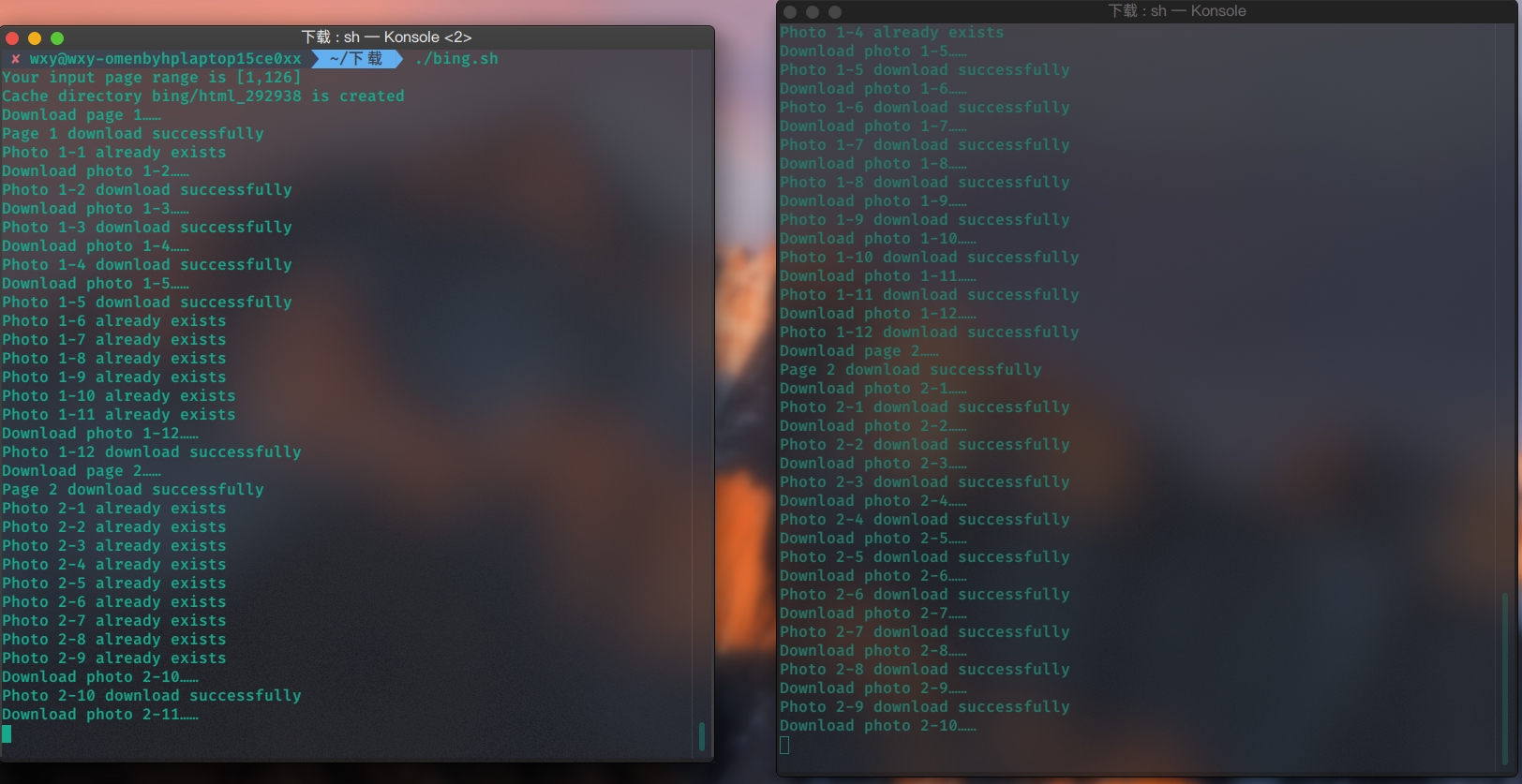
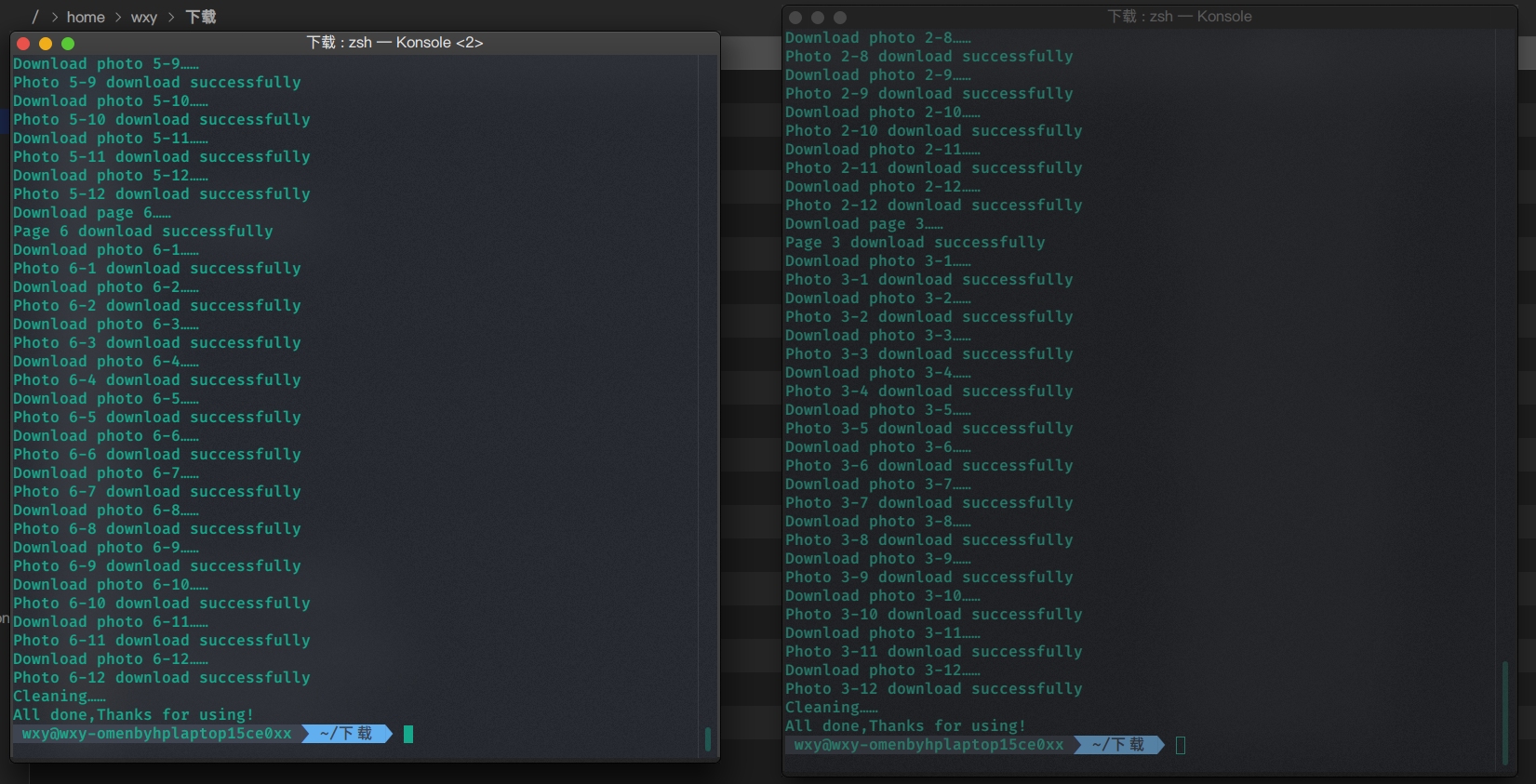
并发执行(自己额外实现的功能,下载的内容有冲突)
终端1:
终端2:
我写的代码,专门考虑了并发的情况,使用当前进程id作为缓冲文件名,从而不会与其他的程序产生冲突。我额外实现了,并发执行时,即使下载的内容有冲突,也不会产生错误。但是可能有一个小问题就是如果第一个程序检测到了a图片没有下载,开始下载了,但是在第一个程序还没下载完成时,刚好第二个程序也检测到了a图片没有下载,可能会重复下载,但是如果第二个程序检测到了a图片已经下载完成,则不会重复下载,所以也无伤大雅,不会产生致命错误。
查看下载的图片:
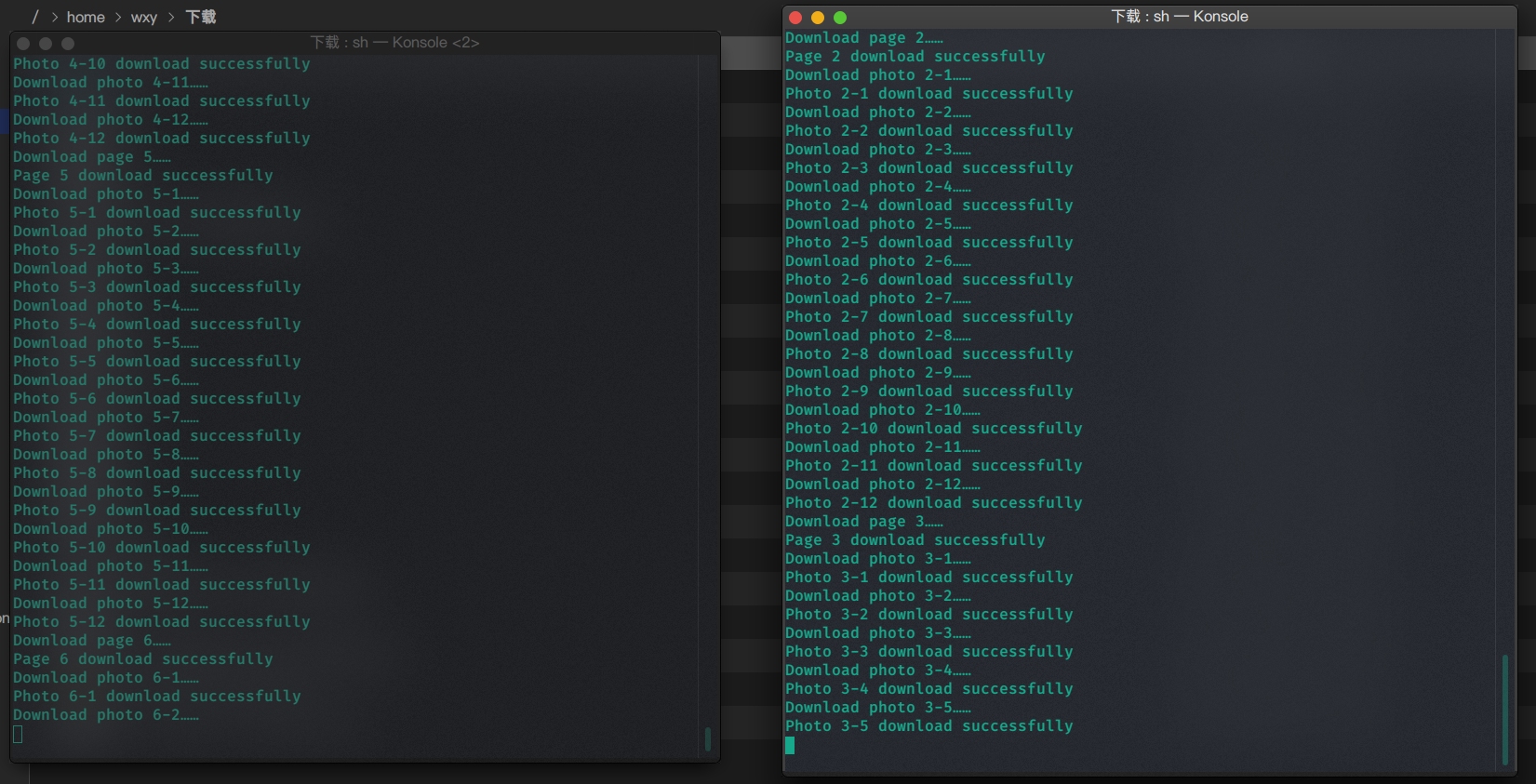
并发执行(下载的内容无冲突)
终端1:
终端2:
如果下载的内容没有冲突就更不会产生任何问题了。
完美下载完成。
查看下载的图片,刚好是72张,1-6页。
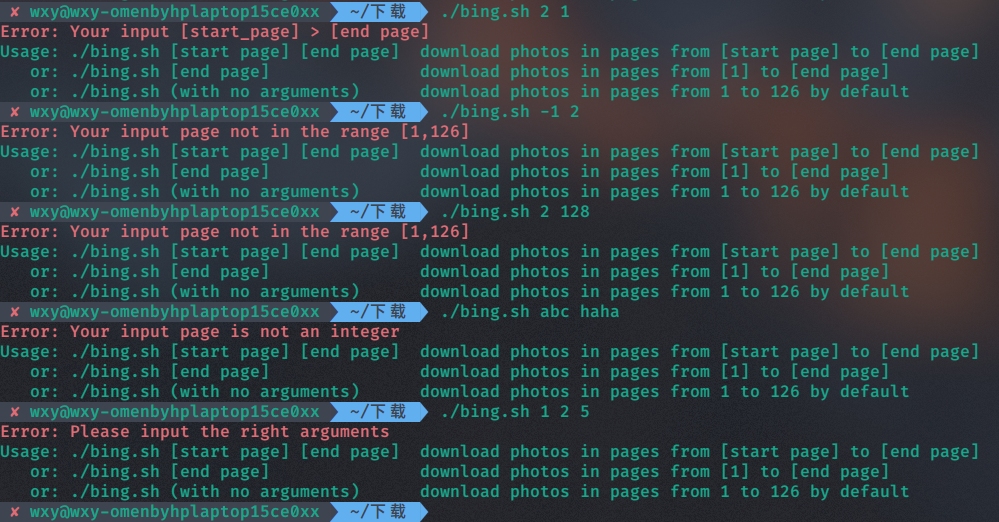
差错处理
各种错误处理的情况:
3、选做:获取更多图片
先访问网址https://bing.ioliu.cn/v1/rand?type=json 查看json文件的格式
把json中我们感兴趣的内容通过正则表达式配合grep、sed、awk命令,将它取出来:
这些都比较简单,根据json的key就很轻松的取出来了
文字介绍
1 cat bing/$$.json | sed 's/.*"copyright":"\(.*\)(.*©.*)"},.*/\1/g'
日期
1 cat bing/$$.json | sed 's/.*"enddate":"\([0-9][0-9][0-9][0-9]\)\([0-9][0-9]\)\([0-9][0-9]\)",.*/\1-\2-\3/g'
网址
1 cat bing/$$.json | sed 's/.*"url":"\(http:.*imageslim\)",.*/\1/g'
详细的代码和注释见最后的附录。
运行程序,依然需要先赋予执行权限。
PS:v2.0在v1.0的基础上进行了修改,优化了部分代码,除了这次的功能,完全保留了v1.0的功能,并且random模式也可以并发,就不展示了。
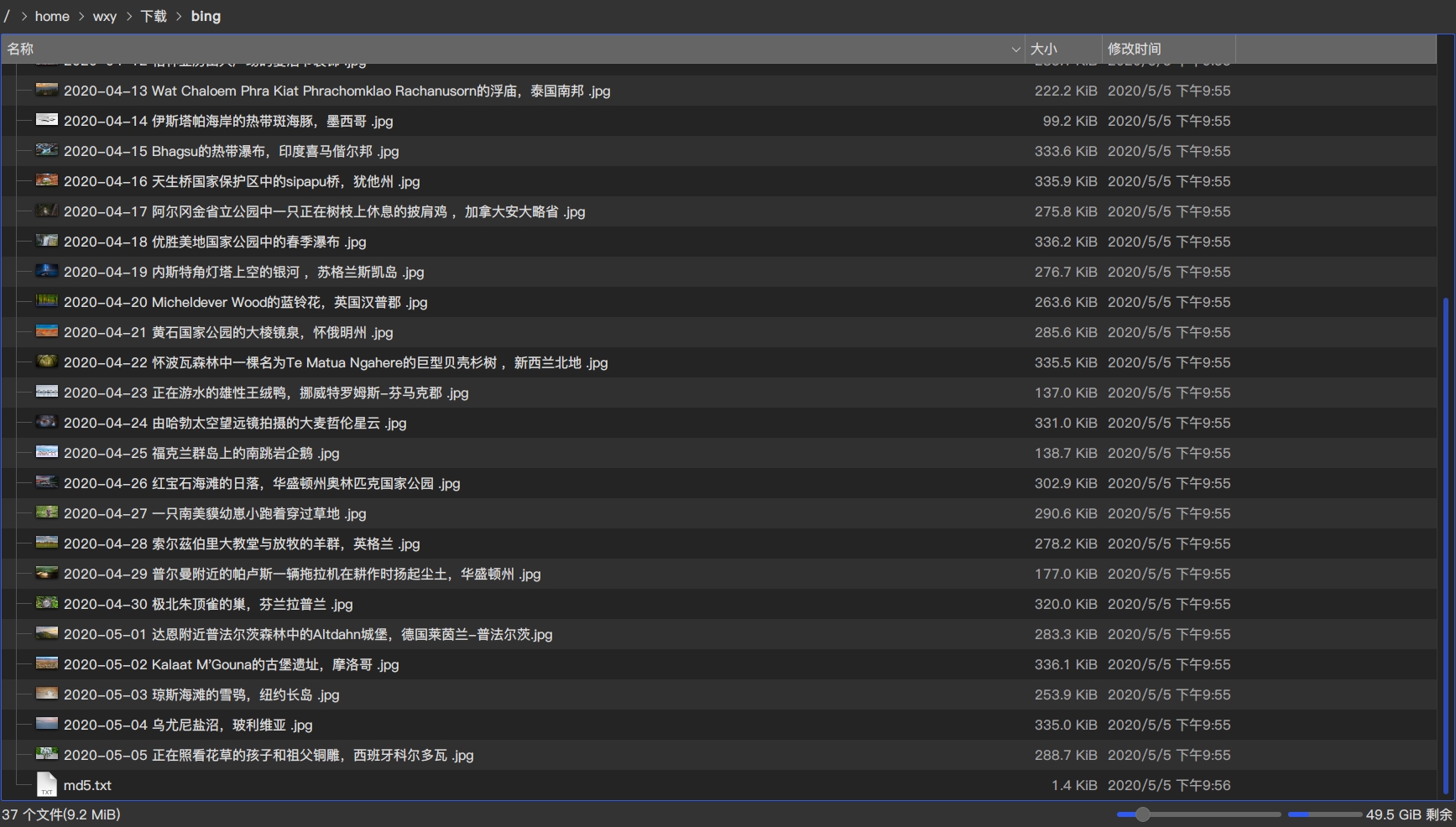
查看下载的图片:
差错处理
各种错误处理的情况:
4、升级版bing.sh 在bing2.sh的基础上升级的v3.0版的bing3.sh,优化了bing2.sh的部分判断逻辑和代码,相较于bing2.sh移除了diff和cmp比较,使用了更为高效的md5比较,且将md5校验信息存到文件中,供下次使用,加速判断。
运行截图:
这里都是展示了更为高级的并发下载的情况,非并发就不再展示了。
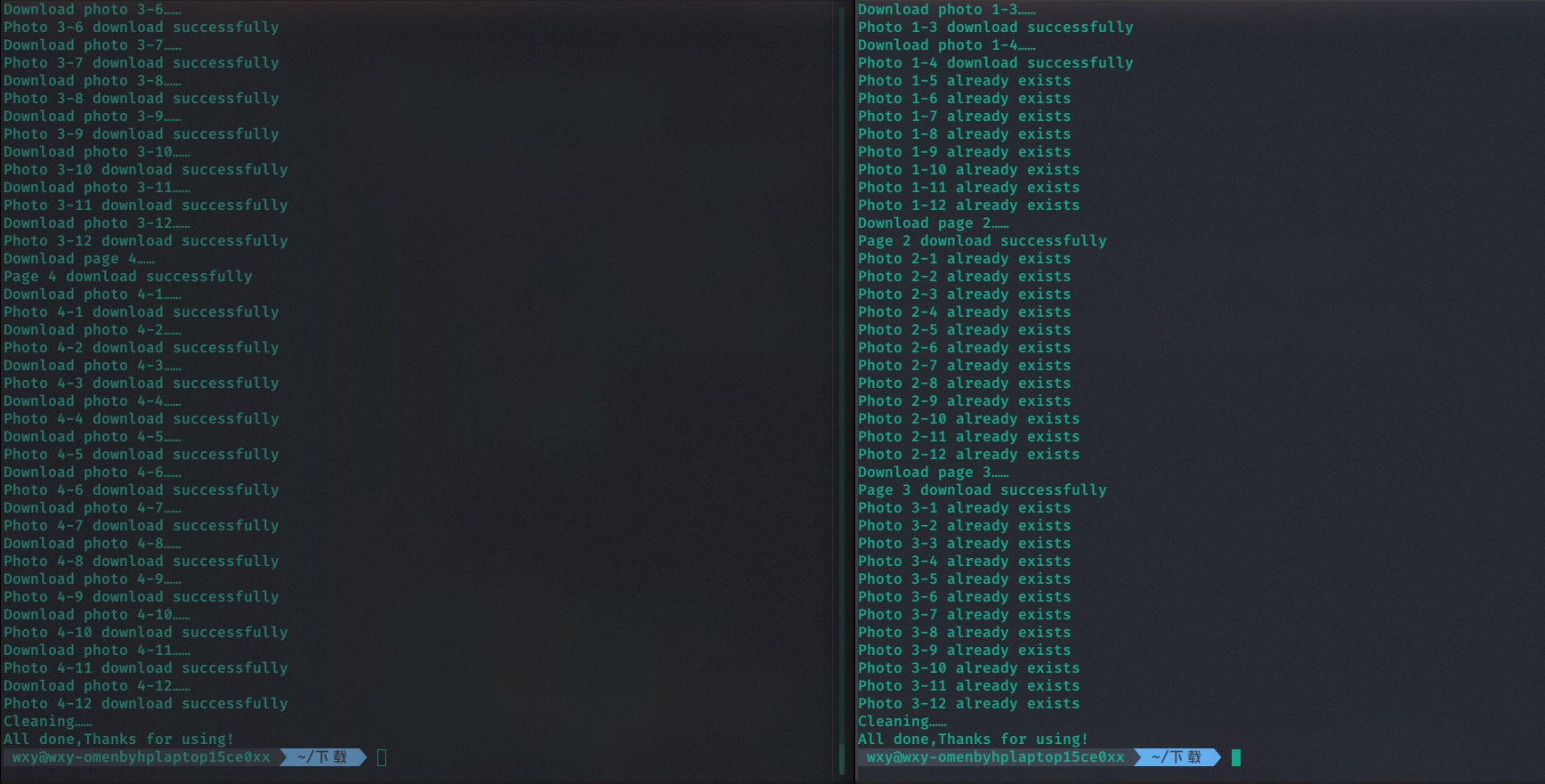
两个终端分别进行:
结果:
完美执行成功,且已经下载过的不会重复下载:
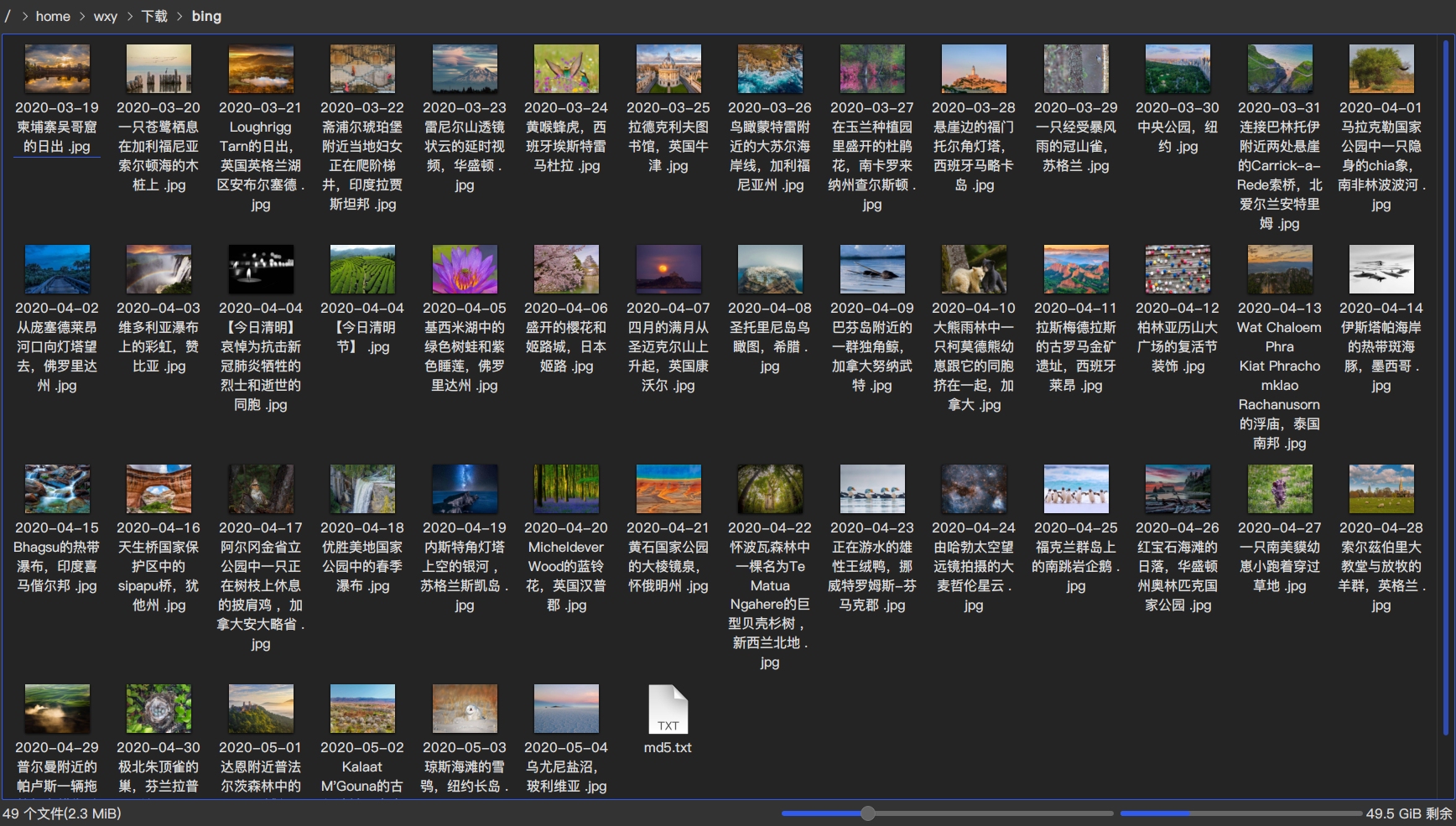
查看图片:
刚好1-4页48个图片加1个md5校验文件,共49个文件
md5校验文件md5.txt也成功生成了。
两个终端分别进行:
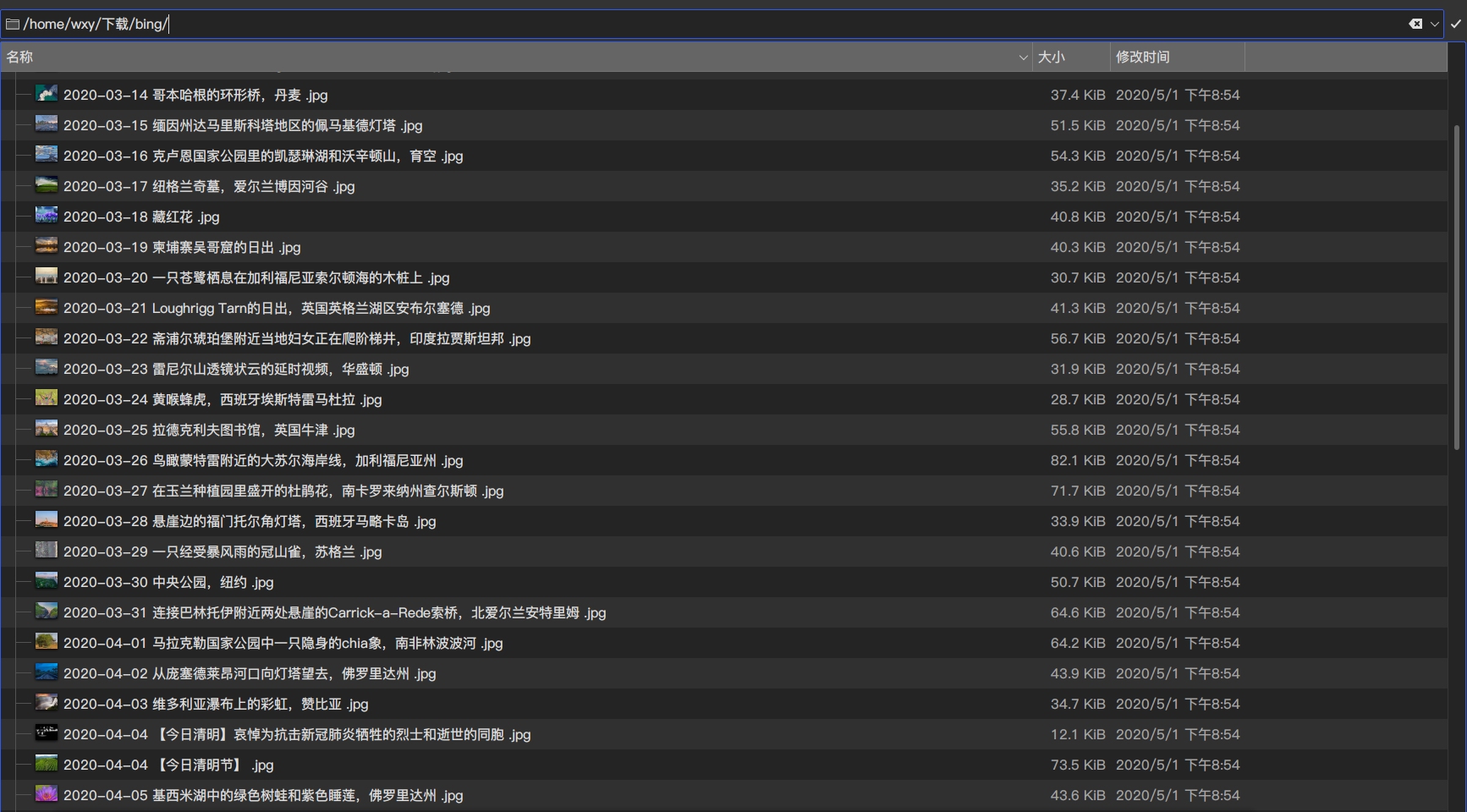
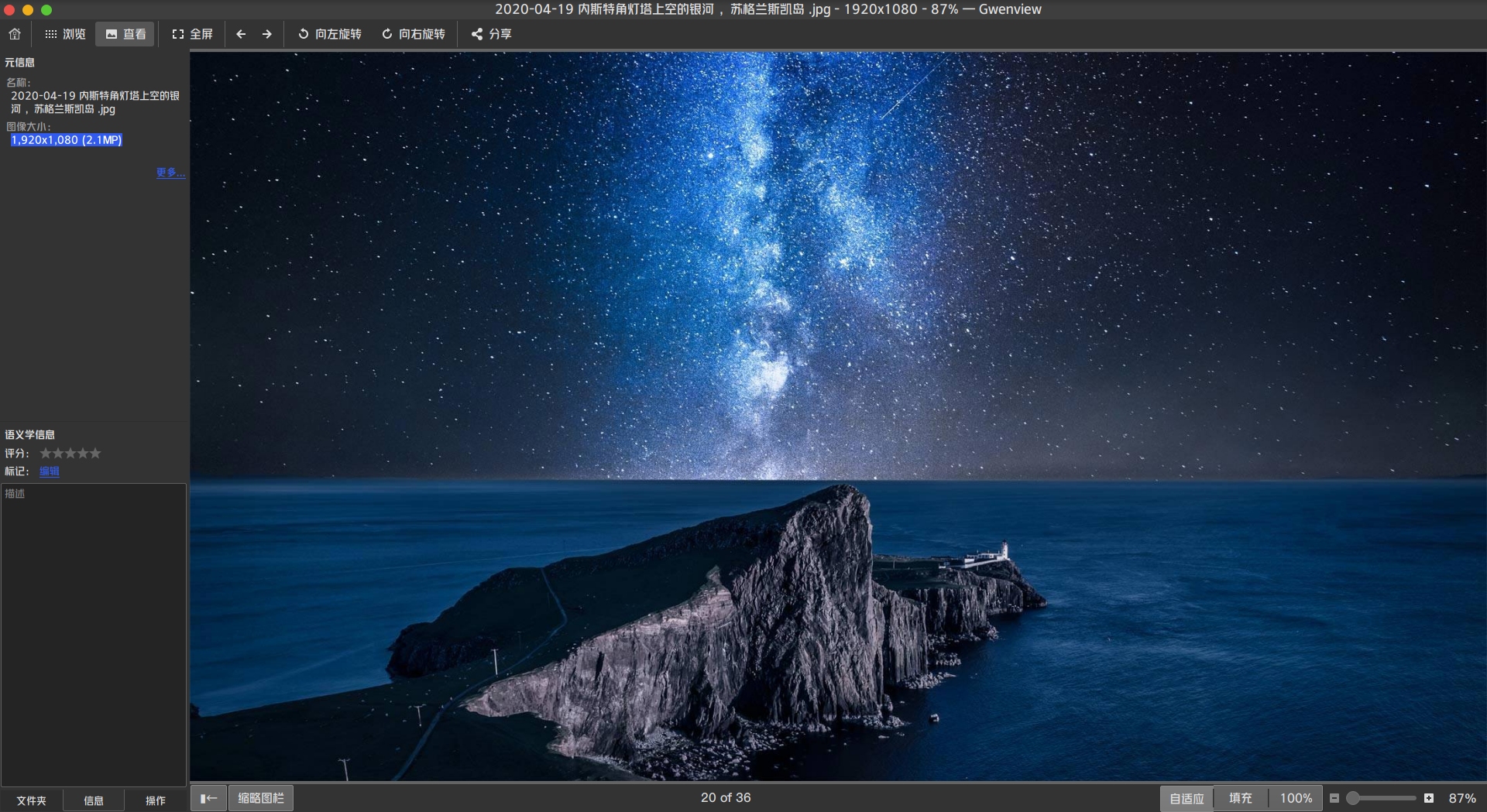
5、小修复 修复了分辨率过小,导致下载的图片不清晰的问题,现在分辨率统一为1920x1080。
由文件大小也可以看出,分辨率已经给更改。
打开图片查看,图片已经很清晰了,分辨率为1920x1080。
四、实验总结及感受 在这次实验中,明显感受到了shell脚本程序的编程和C语言等有很大的差别,尤为要注意各种双引号,单引号,空格啊之类的,拉下来就完全错误。在实验中还遇到了一个很有意思的小问题,就是echo命令如果后面的变量中有换行的话,直接使用:
会将换行变成空格,但是如果加上双引号括起来,就能正常输出换行了:
在实验中还熟悉了各种分支循环命令的使用,在shell中的printf格式化输出,并且复习了前面学习的正则表达式和grep、sed、awk文本处理三剑客,收获很大。
五、项目地址 本项目的源码、可执行程序均已经存放于我的Github,欢迎下载查看:
六、附录 1、net.sh 点击查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 # 获取时间 date_time=`date '+%Y-%m-%d %H:%M'` # 这一分钟开始时的TCP报文数 data1=`netstat --statistics | grep '[0-9][0-9]* segments [rs][e][cn]'` # 发送 send1=`echo $data1 | awk '{print $4}'` # 接收 recv1=`echo $data1 | awk '{print $1}'` # 等60s sleep 60 # 这一分钟结束时的TCP报文数 data_temp=`netstat --statistics | grep '[0-9][0-9]* segments [rs][e][cn]'` # 发送 send_temp=`echo $data_temp | awk '{print $4}'` # 接收 recv_temp=`echo $data_temp | awk '{print $1}'` # 这一分钟内发送的TCP报文数 send=`expr $send_temp - $send1` # 这一分钟内接收的TCP报文数 recv=`expr $recv_temp - $recv1` # 这一分钟内收发TCP报文总数 sum_temp=`expr $send + $recv` # 输出,第一次输出不加最后的符号 printf '%-16s%8s%8s%8s\n' "$date_time" "$send" "$recv" "$sum_temp" while true do # 获取时间 date_time=`date '+%Y-%m-%d %H:%M'` # 等60s sleep 60 # 一分钟后的TCP报文数 data2=`netstat --statistics | grep '[0-9][0-9]* segments [rs][e][cn]'` # 发送 send2=`echo $data2 | awk '{print $4}'` # 接收 recv2=`echo $data2 | awk '{print $1}'` # 这一分钟内发送的TCP报文数 send=`expr $send2 - $send_temp` # 这一分钟内接收的TCP报文数 recv=`expr $recv2 - $recv_temp` # 这一分钟内收发TCP报文总数 sum2=`expr $send + $recv` # 判断最后的符号 # 后-前>10,为+ if [ `expr $sum2 - $sum_temp` -gt 10 ] then sign='+' # 前-后>10,为- elif [ `expr $sum_temp - $sum2` -gt 10 ] then sign='-' # 其他情况,为空格 else sign=' ' fi # 输出 printf '%-16s%8s%8s%8s%5s\n' "$date_time" "$send" "$recv" "$sum2" "$sign" # 保留上一次的数据,用于下一次比较 send_temp=$send2 recv_temp=$recv2 sum_temp=$sum2 done
2、bing.sh 点击查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 # 错误代号: # 1: 参数输入格式错误 # 2: 输入的页数非整数 # 3: 输入的页数范围不在[1,126] # 4: 开始页数<结束页数 # 5: 获取下载页面失败 # 6: 获取下载图片失败 NONE="\e[0m" RED="\e[0;31m" # 读取命令行参数,并进行错误处理 if [ $# = 0 ] then start_page=1 end_page=126 # 额外增加了一个,如果只输入一个参数,代表从第1页到输入的参数的页数 elif [ $# = 1 ] then start_page=1 end_page=$1 elif [ $# = 2 ] then start_page=$1 end_page=$2 else printf $RED'Error: Please input the right arguments\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from 1 to 126 by default" exit 1 fi # 输入的页数非整数 if ! expr $start_page + 0 > /dev/null 2>&1 || ! expr $end_page + 0 > /dev/null 2>&1 then printf $RED'Error: Your input page is not an integer\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from 1 to 126 by default" exit 2 fi # 输入的页数范围不在[1,126] if [ $start_page -lt 1 -o $end_page -lt 1 -o $start_page -gt 126 -o $end_page -gt 126 ] then printf $RED'Error: Your input page not in the range [1,126]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from 1 to 126 by default" exit 3 fi # 开始页数<结束页数 if [ $start_page -gt $end_page ] then printf $RED'Error: Your input [start_page] > [end page]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from 1 to 126 by default" exit 4 fi echo "Your input page range is [$start_page,$end_page]" # 判断并创建目录 if [ ! -d bing ] then mkdir bing echo "Work directory bing is created" fi # 缓存目录这里使用当前进程ID号作为区分,防止受到影响,下面下载图片使用$$.jpg作为缓存也是同样的道理 if [ ! -d bing/html_$$ ] then mkdir bing/html_$$ echo "Cache directory bing/html_$$ is created" fi # 对页范围内的循环下载 for i in `seq $start_page $end_page` do # 判断是否已经下载 if [ ! -f bing/html_$$/$i.html ] then echo "Download page $i……" if wget -O bing/html_$$/$i.html "https://bing.ioliu.cn/?p=$i" > /dev/null 2>&1 then echo "Page $i download successfully" else if [ -f bing/html_$$/$i.html ] then rm bing/html_$$/$i.html fi printf $RED"Error: Page $i download failed\n"$NONE exit 5 fi else echo "Page $i already exists" fi # 获取该页所以图片信息 name_list=`cat bing/html_$$/$i.html | sed 's/<[^<>]*>/\n/g' | awk '/©/ { print $0 }' | sed 's/(.*)//g'` date_list=`cat bing/html_$$/$i.html | sed 's/<[^<>]*>/\n/g' | awk '/[0-9][0-9]*-[0-9][0-9]*-[0-9][0-9]*/ { print $0 }'` url_list=`cat bing/html_$$/$i.html | sed 's/src="/\n/g' | awk '/^http:/ { print $1 }' | sed -e 's/"><a//g' -e 's/640x480/1920x1080/g'` # 对该页内图片循环下载 for j in `seq 1 12` do # 获取图片信息 name=`echo "$name_list" | awk "NR==$j"` date=`echo "$date_list" | awk "NR==$j"` url=`echo "$url_list" | awk "NR==$j"` file_name="$date $name.jpg" # 清理残留缓存 if [ -f "bing/$$.jpg" ] then rm "bing/$$.jpg" fi # 判断是否已经下载 if [ ! -f "bing/$file_name" ] then echo "Download photo $i-$j……" if wget -O bing/$$.jpg "$url" > /dev/null 2>&1 then mv "bing/$$.jpg" "bing/$file_name" echo "Photo $i-$j download successfully" else printf $RED"Error: Photo $i-$j download failed\n"$NONE exit 6 fi else echo "Photo $i-$j already exists" fi done done # 清理缓存 echo "Cleaning……" if [ -d bing/html_$$ ] then rm -r bing/html_$$ fi echo "All done,Thanks for using!"
3、bing2.sh 点击查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 # 错误代号: # 1: 参数输入格式错误 # 2: 输入的页数非整数 # 3: 输入的页数范围不在[1,126] # 4: 开始页数<结束页数 # 5: 下载页面失败 # 6: 下载图片失败 # 7: 输入的随机次数非整数 # 8: 输入的随机次数<1 # 9: 下载json失败 # 10: 未知错误 NONE="\e[0m" RED="\e[0;31m" # rand=0,代表普通模式;rand>0代表随机模式,rand的数值代表随机的次数 rand=0 # 读取命令行参数,并进行错误处理 if [ $# = 0 ] then start_page=1 end_page=126 # 额外增加了一个,如果只输入一个参数,代表从第1页到输入的参数的页数 elif [ $# = 1 ] then start_page=1 end_page=$1 elif [ $# = 2 ] then # 随机模式 if [ $1 = 'rand' ] then # 判断第二个参数是否为整数 if expr $2 + 0 > /dev/null 2>&1 then # 输入的随机次数<1 if [ $2 -lt 1 ] then printf $RED'Error: Your input [rand times] < 1\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 8 else rand=$2 fi # 输入的随机次数非整数 else printf $RED'Error: Your input [rand times] is not an integer\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 7 fi # 普通模式 else start_page=$1 end_page=$2 # 输入的页数非整数 if ! expr $start_page + 0 > /dev/null 2>&1 || ! expr $end_page + 0 > /dev/null 2>&1 then printf $RED'Error: Your input page is not an integer\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 2 fi # 输入的页数范围不在[1,126] if [ $start_page -lt 1 -o $end_page -lt 1 -o $start_page -gt 126 -o $end_page -gt 126 ] then printf $RED'Error: Your input page not in the range [1,126]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 3 fi # 开始页数<结束页数 if [ $start_page -gt $end_page ] then printf $RED'Error: Your input [start_page] > [end page]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 4 fi fi # 参数输入格式错误 else printf $RED'Error: Please input the right arguments\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 1 fi # 判断并创建工作目录 if [ ! -d bing ] then mkdir bing echo "Work directory bing is created" fi # 普通模式 if [ $rand -eq 0 ] then echo "##############Regular Mode##############" echo "Your input page range is [$start_page,$end_page]" # 对页范围内的循环下载 for i in `seq $start_page $end_page` do # 缓存文件使用当前进程ID号$$.html命名,防止受到影响,下面下载图片使用$$.jpg作为缓存也是同样的道理 echo "Download page $i……" if wget -O bing/$$.html "https://bing.ioliu.cn/?p=$i" > /dev/null 2>&1 then echo "Page $i download successfully" else if [ -f bing/$$.html ] then rm bing/$$.html fi printf $RED"Error: Page $i download failed\n"$NONE exit 5 fi # 获取该页所以图片信息 name_list=`cat bing/$$.html | sed 's/<[^<>]*>/\n/g' | awk '/©/ { print $0 }' | sed 's/(.*)//g'` date_list=`cat bing/$$.html | sed 's/<[^<>]*>/\n/g' | awk '/[0-9][0-9]*-[0-9][0-9]*-[0-9][0-9]*/ { print $0 }'` url_list=`cat bing/$$.html | sed 's/src="/\n/g' | awk '/^http:/ { print $1 }' | sed -e 's/"><a//g' -e 's/640x480/1920x1080/g'` # 对该页内图片循环下载 for j in `seq 1 12` do # 获取图片信息 name=`echo "$name_list" | awk "NR==$j"` date=`echo "$date_list" | awk "NR==$j"` url=`echo "$url_list" | awk "NR==$j"` file_name="$date $name.jpg" # 判断是否已经下载 if [ ! -f "bing/$file_name" ] then echo "Download photo $i-$j……" if wget -O bing/$$.jpg "$url" > /dev/null 2>&1 then mv "bing/$$.jpg" "bing/$file_name" echo "Photo $i-$j download successfully" else printf $RED"Error: Photo $i-$j download failed\n"$NONE exit 6 fi else echo "Photo $i-$j already exists" fi done done # 清理缓存 echo "Cleaning……" rm bing/$$.html # 随机模式 elif [ $rand -gt 0 ] then echo "##############Random Mode##############" echo "Your input rand times is $rand" # 循环随机下载 for k in `seq 1 $rand` do # 获取json if wget -O bing/$$.json "https://bing.ioliu.cn/v1/rand?type=json" > /dev/null 2>&1 then # 获取图片信息 name=`cat bing/$$.json | sed 's/.*"copyright":"\(.*\)(.*©.*)"},.*/\1/g'` date=`cat bing/$$.json | sed 's/.*"enddate":"\([0-9][0-9][0-9][0-9]\)\([0-9][0-9]\)\([0-9][0-9]\)",.*/\1-\2-\3/g'` url=`cat bing/$$.json | sed 's/.*"url":"\(http:.*imageslim\)",.*/\1/g'` file_name="$date $name.jpg" # 判断是否已经下载,先用文件名判断 if [ ! -f "bing/$file_name" ] then echo "Download photo $k……" if wget -O bing/$$ "$url" > /dev/null 2>&1 then # 文件名不存在的,判断是否有文件大小相同的和内容相同的 same=0 for file in bing/*.jpg do # 先判断bing文件夹中是否有.jpg文件,如果没有的话*不会被替换,会出错 if [ "$file" = 'bing/*.jpg' ] then break fi # 先比较文件大小是否相同,加快速度 if [ `stat -c%s "$file"` = `ls -l "bing/$$" | awk '{ print $5 }'` ] then # 大小相同再比较内容 # diff命令主要用于比较文本文件,比较二进制文件效率较低 # if diff "$file" "bing/$$" > /dev/null # then # # 相同 # same=1 # break # fi # md5sum计算文件md5值,进行比较 # if [ `md5sum "$file" | awk '{ print $1 }'` = `md5sum "bing/$$" | awk '{ print $1 }'` ] # then # # 相同 # same=1 # break # fi # cmp命令是逐字节比较 if cmp -s "$file" "bing/$$" then # 相同 same=1 break fi fi done if [ $same = 1 ] then rm bing/$$ echo "Photo $k already exists" else mv "bing/$$" "bing/$file_name" echo "Photo $k download successfully" fi else printf $RED"Error: Photo $k download failed\n"$NONE exit 6 fi else echo "Photo $k already exists" fi else if [ -f bing/$$.json ] then rm bing/$$.json fi printf $RED"Error: Json $k download failed\n"$NONE exit 9 fi done # 清理缓存 echo "Cleaning……" rm bing/$$.json # 未知错误 else printf $RED"Error: Unkonwn error\n"$NONE exit 10 fi echo "All done,Thanks for using!"
4、bing3.sh 点击查看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 # 错误代号: # 1: 参数输入格式错误 # 2: 输入的页数非整数 # 3: 输入的页数范围不在[1,126] # 4: 开始页数<结束页数 # 5: 下载页面失败 # 6: 下载图片失败 # 7: 输入的随机次数非整数 # 8: 输入的随机次数<1 # 9: 下载json失败 # 10: 未知错误 NONE="\e[0m" RED="\e[0;31m" # rand=0,代表普通模式;rand>0代表随机模式,rand的数值代表随机的次数 rand=0 # 读取命令行参数,并进行错误处理 if [ $# = 0 ] then start_page=1 end_page=126 # 额外增加了一个,如果只输入一个参数,代表从第1页到输入的参数的页数 elif [ $# = 1 ] then start_page=1 end_page=$1 elif [ $# = 2 ] then # 随机模式 if [ $1 = 'rand' ] then # 判断第二个参数是否为整数 if expr $2 + 0 > /dev/null 2>&1 then # 输入的随机次数<1 if [ $2 -lt 1 ] then printf $RED'Error: Your input [rand times] < 1\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 8 else rand=$2 fi # 输入的随机次数非整数 else printf $RED'Error: Your input [rand times] is not an integer\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 7 fi # 普通模式 else start_page=$1 end_page=$2 # 输入的页数非整数 if ! expr $start_page + 0 > /dev/null 2>&1 || ! expr $end_page + 0 > /dev/null 2>&1 then printf $RED'Error: Your input page is not an integer\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 2 fi # 输入的页数范围不在[1,126] if [ $start_page -lt 1 -o $end_page -lt 1 -o $start_page -gt 126 -o $end_page -gt 126 ] then printf $RED'Error: Your input page not in the range [1,126]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 3 fi # 开始页数<结束页数 if [ $start_page -gt $end_page ] then printf $RED'Error: Your input [start_page] > [end page]\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 4 fi fi # 参数输入格式错误 else printf $RED'Error: Please input the right arguments\n'$NONE echo "Usage: $0 [start page] [end page] download photos in pages from [start page] to [end page]" echo " or: $0 [end page] download photos in pages from [1] to [end page]" echo " or: $0 (with no arguments) download photos in pages from [1] to [126] by default" echo " or: $0 rand [rand times] rand download photos of [rand times]" exit 1 fi # 判断并创建工作目录 if [ ! -d bing ] then mkdir bing echo "Work directory bing is created" fi # 普通模式 if [ $rand -eq 0 ] then echo "##############Regular Mode##############" echo "Your input page range is [$start_page,$end_page]" # 对页范围内的循环下载 for i in `seq $start_page $end_page` do # 缓存文件使用当前进程ID号$$.html命名,防止受到影响,下面下载图片使用$$.jpg作为缓存也是同样的道理 echo "Download page $i……" if wget -O bing/$$.html "https://bing.ioliu.cn/?p=$i" > /dev/null 2>&1 then echo "Page $i download successfully" else if [ -f bing/$$.html ] then rm bing/$$.html fi printf $RED"Error: Page $i download failed\n"$NONE exit 5 fi # 获取该页所以图片信息 name_list=`cat bing/$$.html | sed 's/<[^<>]*>/\n/g' | awk '/©/ { print $0 }' | sed 's/(.*)//g'` date_list=`cat bing/$$.html | sed 's/<[^<>]*>/\n/g' | awk '/[0-9][0-9]*-[0-9][0-9]*-[0-9][0-9]*/ { print $0 }'` url_list=`cat bing/$$.html | sed 's/src="/\n/g' | awk '/^http:/ { print $1 }' | sed -e 's/"><a//g' -e 's/640x480/1920x1080/g'` # 对该页内图片循环下载 for j in `seq 1 12` do # 获取图片信息 name=`echo "$name_list" | awk "NR==$j"` date=`echo "$date_list" | awk "NR==$j"` url=`echo "$url_list" | awk "NR==$j"` file_name="$date $name.jpg" # 判断是否已经下载 if [ ! -f "bing/$file_name" ] then echo "Download photo $i-$j……" if wget -O bing/$$.jpg "$url" > /dev/null 2>&1 then same=0 # 先判断md5文件是否存在,如果不存在,说明bing空目录,直接改名 if [ -f "bing/md5.txt" ] then # 文件名不存在的,判断是否有文件大小相同的和md5相同的 cat bing/md5.txt | while read line do # 先比较文件大小是否相同,加快速度 if [ `stat -c%s "bing/$$.jpg"` = `echo "$line" | awk '{ print $1 }'` ] then # md5sum计算文件md5值,进行比较 if [ `md5sum "bing/$$.jpg" | awk '{ print $1 }'` = `echo "$line" | awk '{ print $2 }'` ] then # 相同 same=1 break fi fi done fi if [ $same = 1 ] then rm "bing/$$.jpg" echo "Photo $i-$j already exists" else mv "bing/$$.jpg" "bing/$file_name" echo "Photo $i-$j download successfully" # 生成文件大小和MD5校验信息 echo "`stat -c%s "bing/$file_name"` "`md5sum "bing/$file_name"` >> bing/md5.txt fi else printf $RED"Error: Photo $i-$j download failed\n"$NONE exit 6 fi else echo "Photo $i-$j already exists" fi done done # 清理缓存 echo "Cleaning……" rm bing/$$.html # 随机模式 elif [ $rand -gt 0 ] then echo "##############Random Mode##############" echo "Your input rand times is $rand" # 循环随机下载 for k in `seq 1 $rand` do # 获取json if wget -O "bing/$$.json" "https://bing.ioliu.cn/v1/rand?type=json" > /dev/null 2>&1 then # 获取图片信息 name=`cat bing/$$.json | sed 's/.*"copyright":"\(.*\)(.*©.*)"},.*/\1/g'` date=`cat bing/$$.json | sed 's/.*"enddate":"\([0-9][0-9][0-9][0-9]\)\([0-9][0-9]\)\([0-9][0-9]\)",.*/\1-\2-\3/g'` url=`cat bing/$$.json | sed 's/.*"url":"\(http:.*imageslim\)",.*/\1/g'` file_name="$date $name.jpg" # 判断是否已经下载,先用文件名判断 if [ ! -f "bing/$file_name" ] then echo "Download photo $k……" if wget -O "bing/$$.jpg" "$url" > /dev/null 2>&1 then same=0 # 先判断md5文件是否存在,如果不存在,说明bing空目录,直接改名 if [ -f "bing/md5.txt" ] then # 文件名不存在的,判断是否有文件大小相同的和md5相同的 cat bing/md5.txt | while read line do # 先比较文件大小是否相同,加快速度 if [ `stat -c%s "bing/$$.jpg"` = `echo "$line" | awk '{ print $1 }'` ] then # md5sum计算文件md5值,进行比较 if [ `md5sum "bing/$$.jpg" | awk '{ print $1 }'` = `echo "$line" | awk '{ print $2 }'` ] then # 相同 same=1 break fi fi done fi if [ $same = 1 ] then rm "bing/$$.jpg" echo "Photo $k already exists" else mv "bing/$$.jpg" "bing/$file_name" echo "Photo $k download successfully" # 生成文件大小和MD5校验信息 echo "`stat -c%s "bing/$file_name"` "`md5sum "bing/$file_name"` >> bing/md5.txt fi else printf $RED"Error: Photo $k download failed\n"$NONE exit 6 fi else echo "Photo $k already exists" fi else if [ -f bing/$$.json ] then rm bing/$$.json fi printf $RED"Error: Json $k download failed\n"$NONE exit 9 fi done # 清理缓存 echo "Cleaning……" rm bing/$$.json # 未知错误 else printf $RED"Error: Unkonwn error\n"$NONE exit 10 fi echo "All done,Thanks for using!"