







机器学习 实验 决策树
本文是关于20问读心游戏的决策树代码实现。
一、问题:
以20问读心游戏为例,以ID3算法(即信息增益算法)为基础,构造并绘制决策树,最后可以进行简单的测试游玩.
二、实验环境
- 语言:Python 3.6(Anaconda3)
- IDE:PyCharm 2020.1.1 (Professional Edition)
- Packages:
- python standard library
- numpy:1.16.2
- scipy:1.2.1
- pandas:0.24.2
- networkx:2.4
- graphviz:0.13.2
- matplotlib:3.2.1
三、实验结果
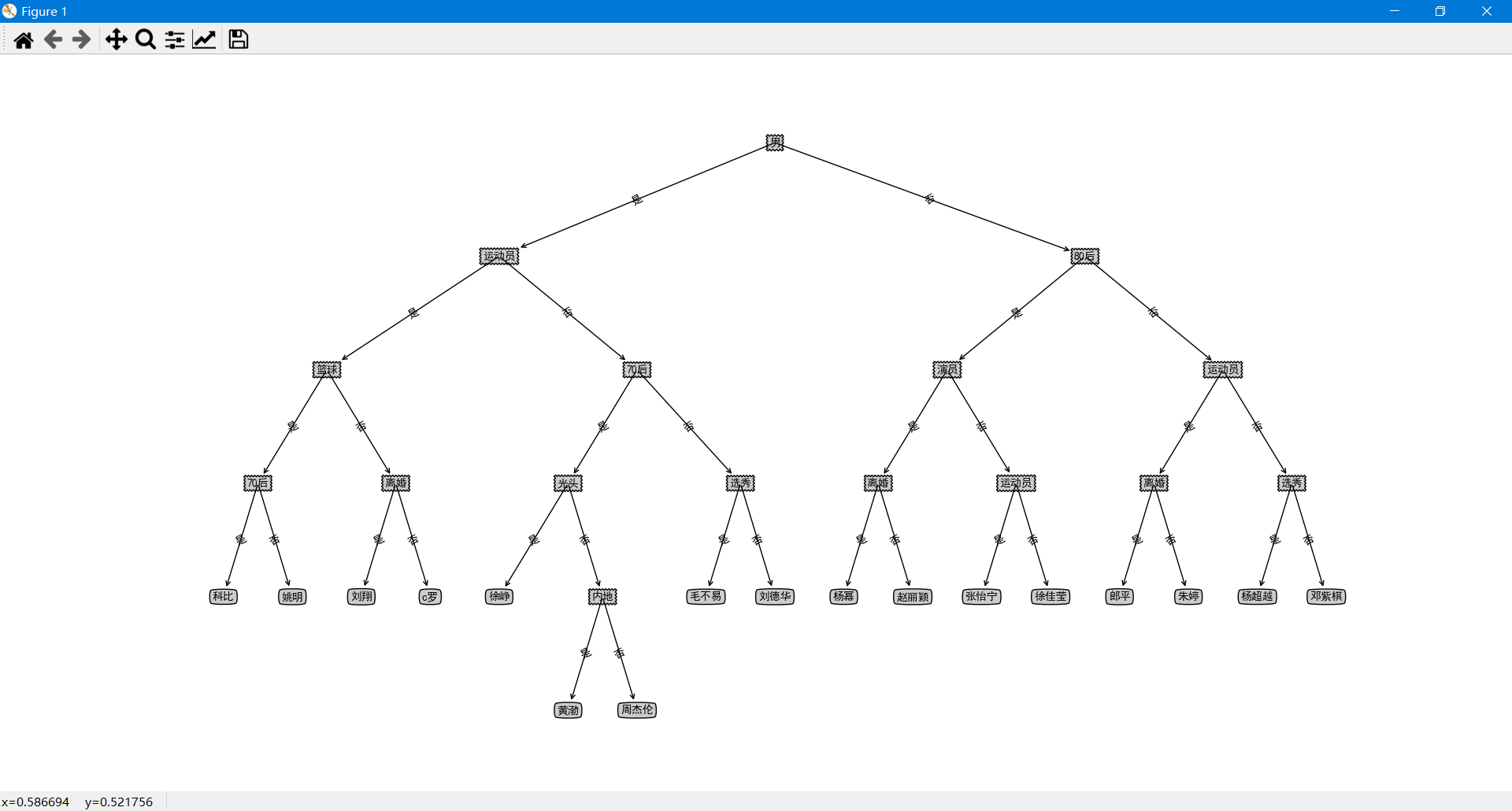
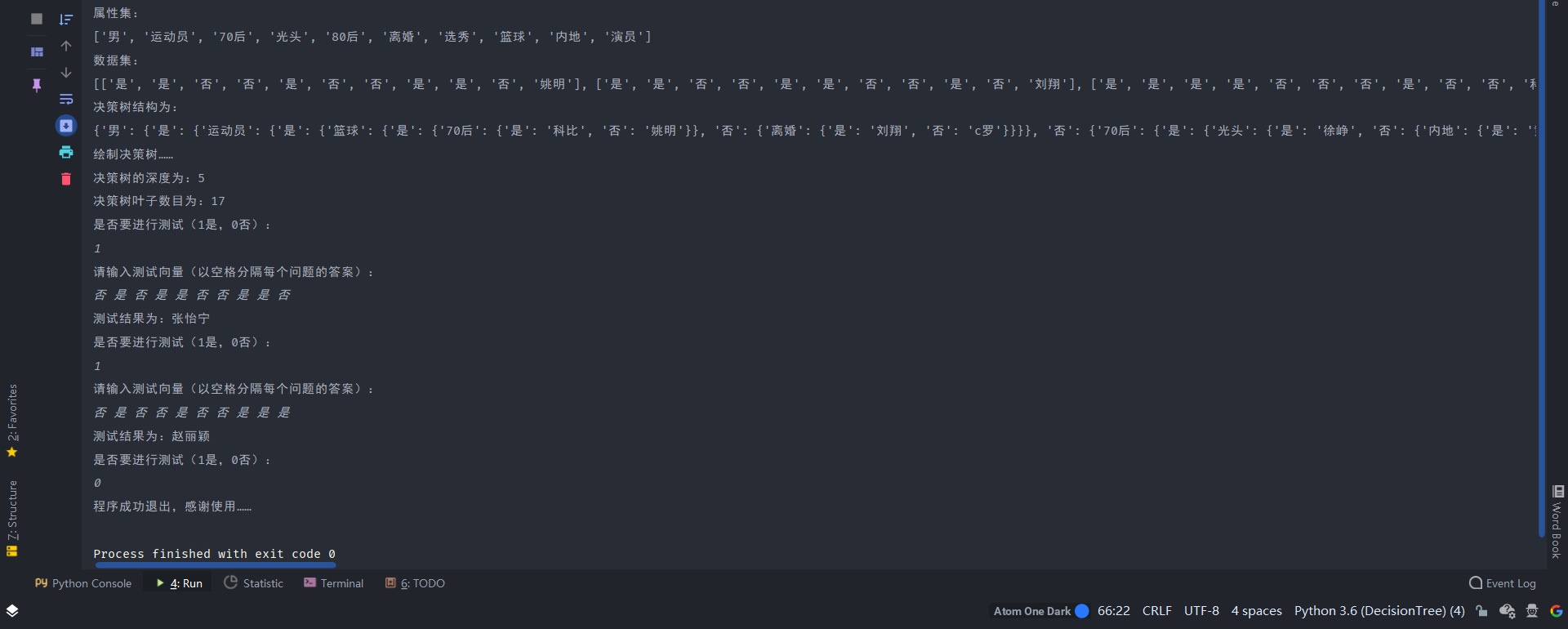
四、项目地址
本项目的源码、可执行程序均已经存放于我的Github,欢迎下载查看:
五、附录
数据集data_set.txt:
点击查看
男 运动员 70后 光头 80后 离婚 选秀 篮球 内地 演员
是 是 否 否 是 否 否 是 是 否 姚明
是 是 否 否 是 是 否 否 是 否 刘翔
是 是 是 是 否 否 否 是 否 否 科比
是 是 否 否 是 否 否 否 否 否 c罗
是 否 否 否 否 否 否 否 否 是 刘德华
是 否 否 否 否 否 是 否 是 否 毛不易
是 否 是 否 否 否 否 否 否 是 周杰伦
是 否 是 否 否 否 否 否 是 是 黄渤
是 否 是 是 否 否 否 否 是 是 徐峥
否 是 否 否 是 否 否 否 是 否 张怡宁
否 是 否 否 否 是 否 否 是 否 郎平
否 是 否 否 否 否 否 否 是 否 朱婷
否 否 否 否 否 否 是 否 是 是 杨超越
否 否 否 否 是 是 否 否 是 是 杨幂
否 否 否 否 否 否 否 否 否 否 邓紫棋
否 否 否 否 是 否 是 否 否 否 徐佳莹
否 否 否 否 是 否 否 否 是 是 赵丽颖
代码decision_tree.py:
1、全局配置
点击查看代码
1 | # -*- coding: utf-8 -*- |
2、构造决策树
点击查看代码
1 | ######################################################## |
3、绘制决策树
点击查看代码
1 | ######################################################## |
4、测试函数
点击查看代码
1 | ######################################################## |
5、开始运行
点击查看代码
1 | ######################################################## |
6、测试游玩
点击查看代码
1 | ######################################################## |



本文为博主「Sekiro」的原创文章
内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议

